CXL Introduction
What is CXL
CXL (Compute Express Link) is a new type of open interconnect standard designed for high-speed communication between processors and high-performance endpoint devices such as GPUs, FPGAs, or other accelerators.
When discussing CXL, it is indispensable to mention the hierarchical storage diagram in computer architecture. In the past, there was a significant gap between HDD disks and memory, but the emergence of SSDs and NVMe devices gradually bridged this gap. Traditional databases have become less sensitive to this difference because the bottleneck of the system has shifted to the CPU side. Therefore, in recent years, everyone has been focusing on column storage, vectorization, and other technologies to reduce memory usage. For many applications, although the latency of NVMe has met the requirements, throughput remains a significant bottleneck, and it cannot completely replace memory. Model training and vector data are very typical scenarios in this regard.
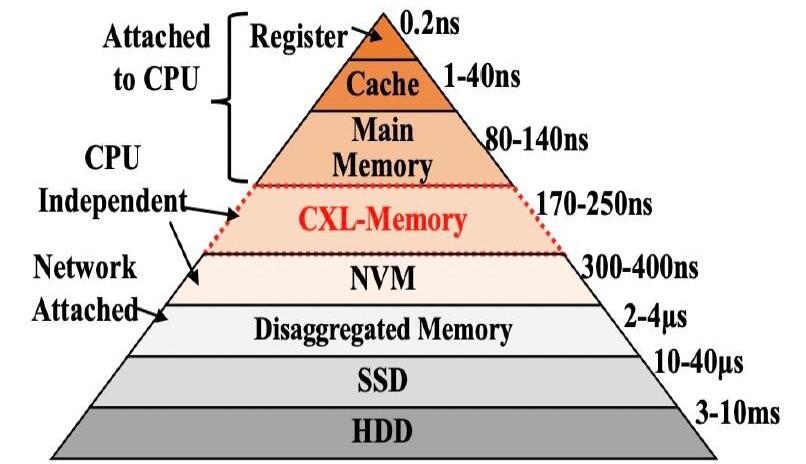
CXL effectively addresses this problem. By mounting the device on the PCIe bus, CXL establishes an interconnection between the device and the CPU, realizing the separation of storage and computation.

CXL Protocols
CXL comprises three different protocols - CXL.io, CXL.cache, and CXL.mem, each serving a different purpose.
CXL.io is built on the physical and link layers of the PCI Express (PCIe) infrastructure. It ensures backward compatibility with the PCIe ecosystem, thus leveraging the advantages of its wide deployment. When a CXL device is connected to a host, these operations are carried out through the CXL.io protocol. It handles input/output operations, and allows discovery, configuration, and basic management of devices.
CXL.cache provides cache coherency between the host processor cache hierarchy and the memory on CXL devices. This coherency allows the host and device to share resources, thereby reducing latency and improving data access rates. This is crucial for high-performance computing workloads such as big data processing and machine learning, which often require frequent access to large amounts of data.
CXL.mem allows the host processor to access a CXL device’s memory at high speed and with low latency. This mechanism allows the host to effectively utilize the device’s memory as a pool of resources, making it highly suitable for applications that require intensive data exchange.
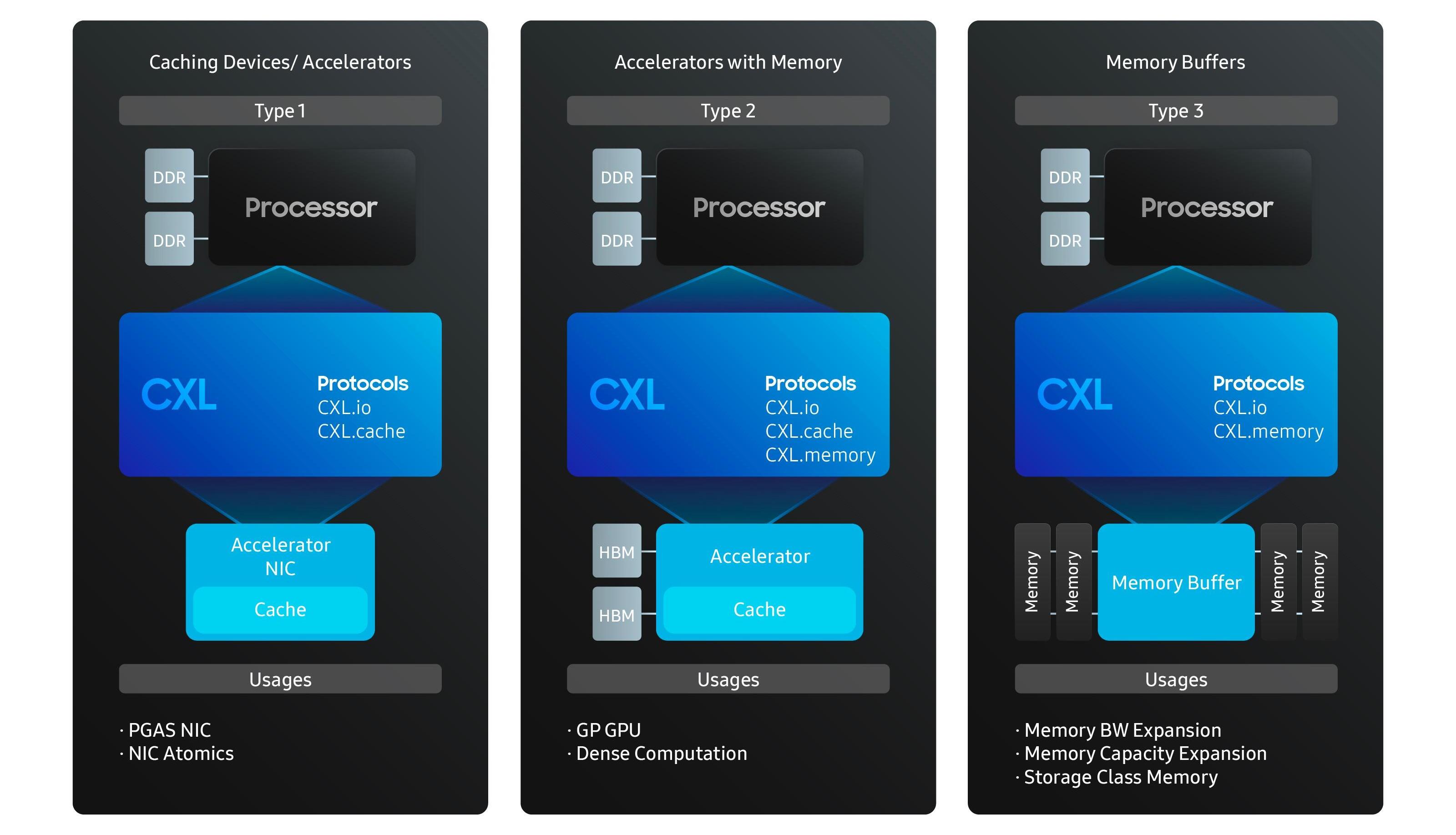
Specifically, CXL mainly defines three types of devices:
CXL Type 1 Device: This type of device includes accelerators and smart network cards. They access host memory via the CXL.cache protocol, maintaining a local cache that’s coherent with the host memory.
CXL Type 2 Device: This category includes devices such as GPUs and FPGAs, which have their own memory such as DDR and HBM. These devices can access the host memory directly like Type 1 devices. Additionally, they can use the CXL.mem protocol to allow the host to access their local address space.
CXL Type 3 Device: These are memory expansion devices that allow the host to access their memory buffer consistently via CXL.mem transactions. Type 3 CXL devices can be used to increase memory capacity and bandwidth.
Maximizing CXL Efficiency
To fully utilize CXL memory, several crucial factors must be taken into account:
Consider the memory hierarchy fully and use RAM or even Cache as the buffer for CXL.
Push down computations as much as possible to reduce the amount of data that the bus needs to handle.
Take the latency of CXL fully into account and design pipelines or use prefetching techniques to reduce the impact of latency on throughput.
Fully exploit the advantages of large memory to minimize the performance impact brought by data exchange in distributed systems.