Google File System
背景
GFS 是 Google 针对大数据处理场景设计的分布式文件系统,Google 对数据量的持续增长的设想如下:
- 需要能够运行在经常故障的物理机环境上。只有做到这点,这个系统才能运行在几百到上千台规模下,并采用相对便宜的服务器硬件
- 大文件居多。存储在 GFS 上的文件的不少都在几个 GB 这样的级别
- 大多数写是append写,即在文件末尾追加
- 性能主要考量是吞吐而不是延时
接口
GFS 以目录树的形式组织文件,但是并没有提供类似 POSIX 标准的文件系统操作。操作只要包含 create, open, write, read, close, delete, append, snapshot,其中 snapshot 用于快速复制一个文件或者目录,允许多个客户端并行追加数据到一个文件。
架构
整体架构上,GFS 由单一的 master 节点、chunkserver 和提供给用户的 client 三大部分组成:
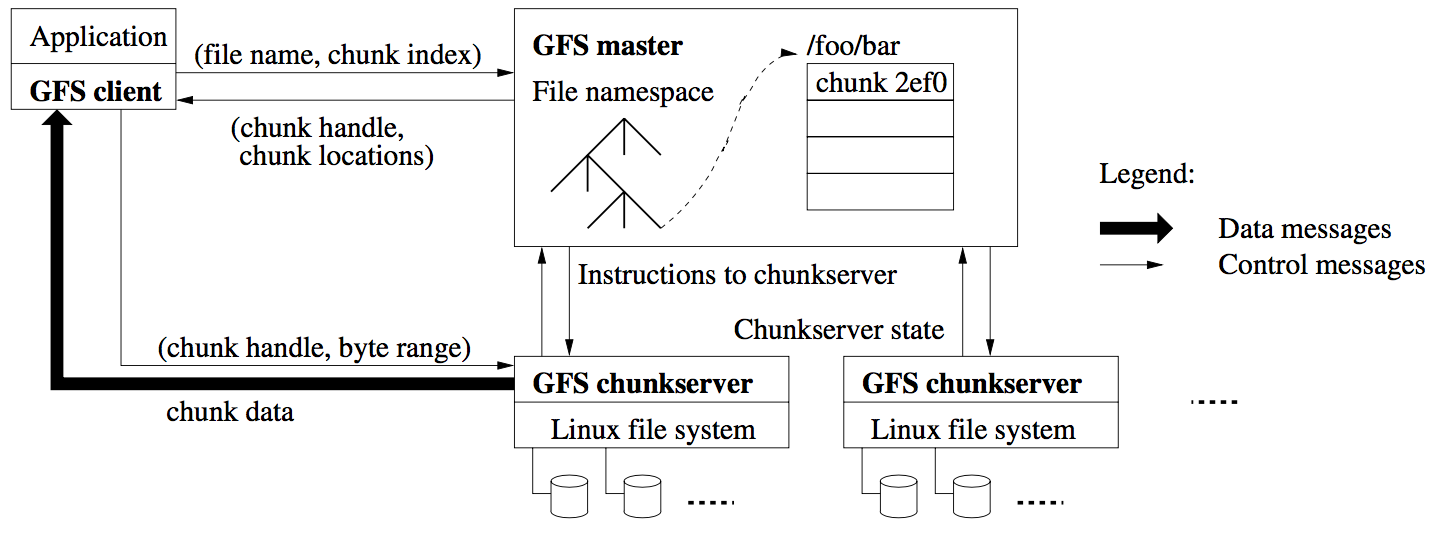
client 与 chunkserver 都不会缓存文件数据,为的是防止数据出现不一致的状况,但是 client 会缓存 metadata 的信息。
master
一方面存储所有的 metadata,负责管理所有的元信息,包括表示文件系统目录结构的 namespace、访问控制信息、文件与 chunk 的映射关系、chunk 的位置信息;另一方面管理 chunk 租约、chunk 迁移(如果 chunkserver 挂掉)、维护与 chunkserver 之间的心跳。
- namespace 采用全内存的数据结构,以提高访问的吞吐
- namespace 是一个查找表(lookup table),并且采用了前缀压缩的方式存储在内存中,它是一个树结构,树中每一个节点(文件名或目录名)都有一个读/写锁。在对文件或目录操作的时候需要获取锁,例如修改
/root/foo/bar,需要获得/root、/root/foo的读锁,/root/foo/bar的写锁 - master 本身并不记录 chunk 的位置,而是在启动的时候,通过收取 chunkserver 的信息来构建。这种设计避免了 master 和 chunkserver 的信息不一致的问题(因为以 chunkserver 为准)
- master 和 chunkserver 通过定期心跳来保持信息同步、感知 chunkserver 故障等
- master 往磁盘上写操作日志,并将这些日志同步到其他物理机保存的方式来确保数据安全性。当前 master 机器故障的时候,可以通过这些日志和 chunkserver 的心跳内容,可以恢复到故障前的状态
- 对于操作日志,会定期在系统后台执行 checkpoint;checkpoint 构建成一个类似B+树、可以快速的 load 到内存中直接使用的结构
- master 需要定期检查每个 chunk 的副本情况,如果副本低于配置值,就需要将通知 chunkserver 进行复制;如果存在一些多余的 chunk (file 已经被删除了),就需要做一些清理工作
chunkserver
每个 chunk 有一个 64 位标识符(chunk handle),它是在 chunk 被创建时由 master 分配的,每一个 chunk 会有多个副本,分别在不同的机器上,每个副本会以 Linux 文件的形式存储在 chunkserver 的本地磁盘上。
GFS 中将 chunk 的大小定为 64 MB,它比一般的文件系统的块大小要大。优点:减少 metadata 的数量、减少 client 与 master 的交互、client 可以在一个 chunk 上执行更多的操作,通过 TCP 长连接减少网络压力;缺点:如果在一个 chunk 上有一个可执行文件,同时有许多 client 都要请求执行这个文件,它的压力会很大。
chunk 的位置信息在 master 中不是一成不变的,master 会通过定期的 heartbeat 进行更新,这样做能够减小开销,这样做就不用 master 与 chunkserver 时刻保持同步通信(包括 chunkserver 的加入、退出、改名、宕机、重启等)。chunkserver 上有一个 final word,它表示了哪个 chunk 在它的磁盘上,哪个 chunk 不在。
一致性模型
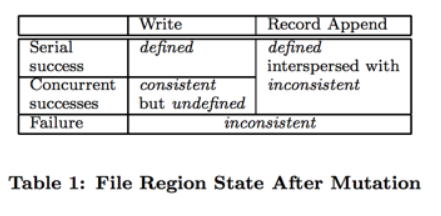
defined:状态已定义,从客户端角度来看,客户端完全了解已写入集群的数据
consistent:客户端来看chunk多副本的数据完全一致,但不一定defined
- 串行写:客户端自己知道写入文件范围以及写入数据内容,且本次写入在数据服务器的多副本上均执行成功,每个客户端的写操作串行执行,因此最终结果是
defined - 并行写:每次写入在数据服务器的多副本上均执行成功,所以结果是
consistent,但客户端无法得知写操作的执行顺序,即使每次操作都成功,客户端无法确定在并发写入时交叉部分,所以是undefined - 追加写:客户端能够根据 offset 确切知道写入结果,无论是串行追加还是并发追加,其行为是
defined,追加时至少保证一次副本写成功,如果存在追加失败,则多个副本之间某个范围的数据可能不一致,因此是interspersed with inconsistent。
GFS 租约
GFS 使用租约机制 (lease) 来保障 mutation (指的是改变了 chunk 的内容或者 metadata,每一次 mutation 都应该作用于所有的备份) 的一致性:多个备份中的一个持有 lease,这个备份被称为 primary replica (其余的备份为 secondary replicas),GFS 会把所有的 mutation 都序列化(串行化),让 primary 执行,secondary 也按相同顺序执行,primary 是由 master 选出来的,一个 lease 通常 60 秒会超时。
写流程
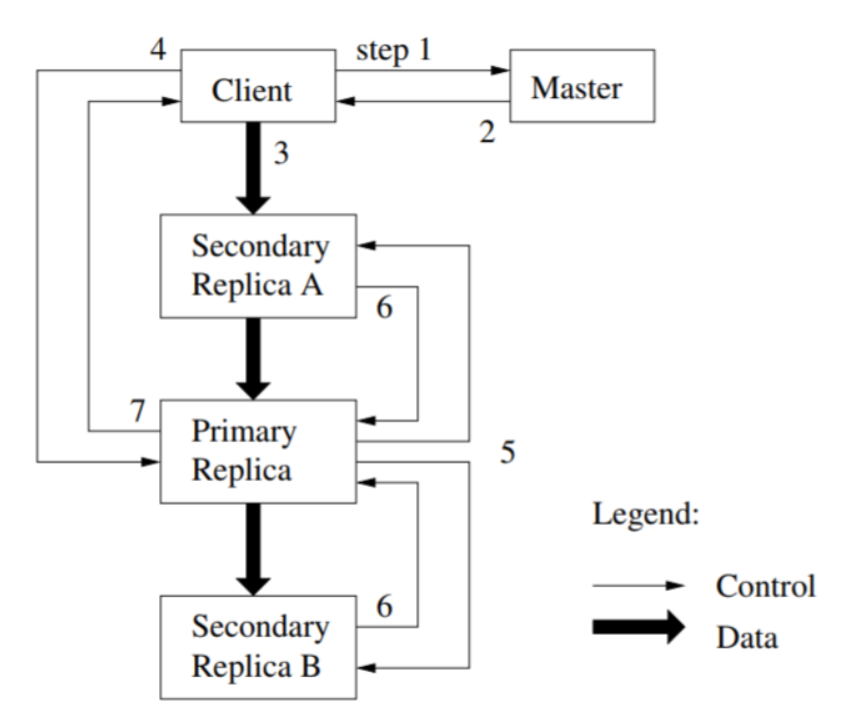
- client 向 master 请求持有 lease 的 chunk (primary replica) 位置和其他 replicas 的位置(如果没有 chunk 持有 lease,那么 master 会授予其中一个 replica 一个 lease)
- master 返回 primary 的信息和其他 replicas 的位置,然后 client 将这些信息缓存起来(只有当 primary 无法通信或者该 primary replica 没有 lease 了,client 才会向 master 再次请求)
- client 会将数据发送到所有的 replicas,每个 chunkserver 会把数据存在 LRU 缓存中
- 在所有的 replicas 都收到了数据之后,client 会向 primary 发送写请求。primary 会给它所收到的所有 mutation 分配序列号(这些 mutation 有可能不是来自于同一个 client),它会在自己的机器上按序列号进行操作
- primary 给 secondaries 发送写请求,secondaries 会按相同的序列执行操作
- secondaries 告知 primary 操作执行完毕
- primary 向 client 应答,期间的错误也会发送给 client,client 错误处理程序 (error handler) 会重试失败的 mutation
读流程
client 向 master 发出 A 文件的读请求
master 收到后返回 A 文件的 chunk handler 和 chunk 的位置
client 携带 chunk handle 以及位偏移向对应的 chunkserver 发出请求
chunkserver 读取并返回数据至 client
参考
- Ghemawat, Sanjay, Howard Gobioff, and Shun-Tak Leung. “The Google file system.” (2003).
Google File System