Google Percolator
背景
Percolator 事务模型是 Google 内部用于 Web 索引更新的业务提出的分布式事务协议,构建在 BigTable 之上,总体来说就是一个经过优化的二阶段提交的实现。使用基于 Percolator 的增量处理系统代替原有的批处理索引系统后,Google 在处理同样数据量的文档时,将文档的平均搜索延时降低了50%。
2PC
传统的 2PC 简单描述一下就是两步:
- 发起事务:事务管理器会发出 Prepare 请求,要求参与者记录日志,进行资源的检查和锁定
- 确认/取消事务:当请求得到所有参与者的成功确认后,事务管理器会发出 Commit 请求,执行真正的操作;如果第一步中只要有一个执行者返回失败,则取消事务
这样会有两个问题,一个就是单点故障:如果事务管理器发生故障,数据库会一直阻塞下去。尤其是在第二阶段发生故障的话,所有参与者还都处于锁定事务资源的状态中,从而无法继续完成事务操作;另一个就是存在数据不一致的情况:在第二阶段,当事务管理器向参与者发送 Commit 请求之后,发生了局部网络异常,导致只有部分参与者接收到请求,但是其他参与者未接到请求所以无法提交事务,整个系统就会出现数据不一致性的现象。
Percolator 事务流程
Percolator 事务是一个经过优化的 2PC 的实现,进行了一个二级锁的优化,也分为两个阶段:预写(Pre-write)和提交(Commit)。另外,所有启用了 Percolator 事务的表中,每一个 Column Family 都会预先增加两个列,分别是:
- lock:存储事务过程中的锁信息
- write:存储当前行可见(最近一次提交)的版本号
另外,为了简化场景,假设存储用户数据的列只有一个,名为 data。
Pre-write
客户端从 TSO 获取时间戳,记为 start_ts,并向 Percolator Worker 发起 Pre-write 请求。
在该事务包含的所有写操作中选取一个作为主(primary)操作,其余的作为次(secondary)操作。主操作将作为整个事务的互斥点,标记事务的状态。
先预写主操作,成功后再预写次操作。在预写过程中,对每一个写操作都要执行检查:
- 检查写入的行对应的 lock 列是否有锁,如果有,说明其他事务正在写,直接取消整个事务
- 检查写入的行对应的 write 列版本号是否晚于 start_ts,如果是,说明有版本冲突,直接取消整个事务
检查通过后,以 start_ts 作为版本号将数据写入 data 列,对操作行加锁,即更新 lock 列的锁信息:主操作行的 lock 直接标为primary,次操作行的 lock 则标为主操作行的键和列名。不更新write列,亦即此时写入的数据仍然不可见。
Commit
客户端从 TSO 获取时间戳,记为 commit_ts,并向 Percolator Worker 发起 Commit 请求。
检查主操作行对应的 lock 列所在的 primary 标记是否存在,如果不存在则失败,取消事务;如果存在则继续。
以 commit_ts 作为版本号,将 start_ts 更新到 write 列中。也就是说在本阶段完成后,预写阶段写入的数据将会可见。
对该行解锁,即删除 lock 列的 primary 信息。
若步骤 1~4 均成功,说明主操作行成功,代表整个事务实际上已经提交。接下来更新每个 secondary 即可,即重复步骤3、4的更新 write 列和清除 lock 列操作。secondary 的 commit 是可以异步进行的,只是在异步提交进行的过程中,如果此时有读请求,可能会需要做一下锁的清理工作。
案例
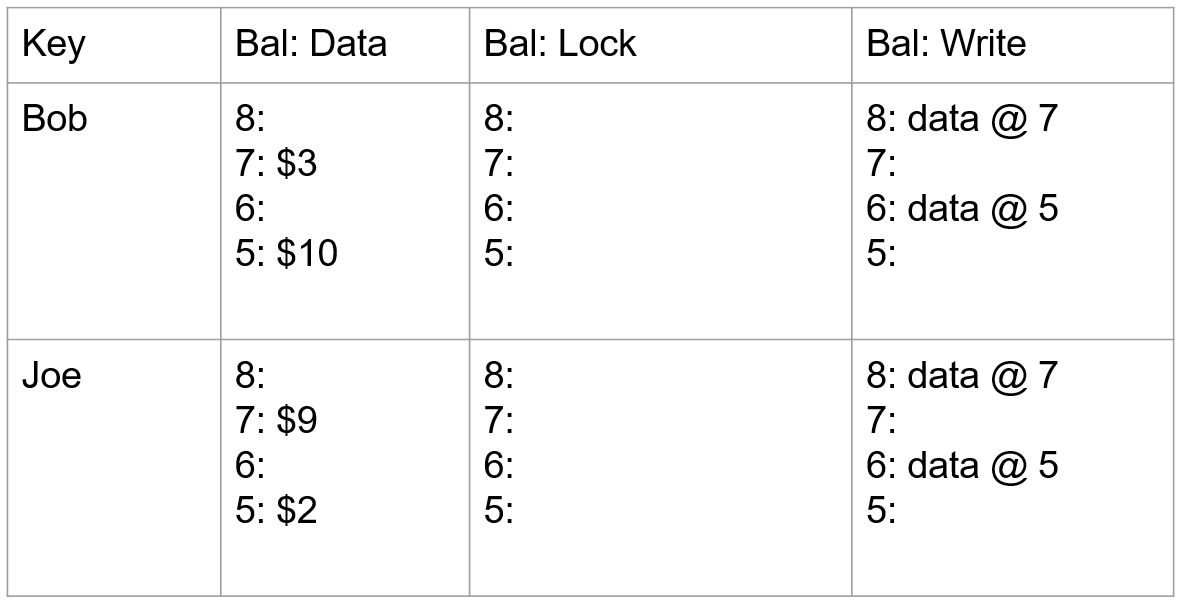
银行转账,Bob 向 Joe 转账 7 元。该事务于 start_ts=7 开始,commit_ts=8 结束,Key 为 Bob 和 Joe 的行可能在不同的分片上。具体过程如下:
- 首先查询 write 列获取最新时间戳数据,获取到 data@5,然后从 data 列里面获取时间戳为 5 的数据,初始状态下,Bob 的帐户下有 10,Joe 的帐户下有 2。
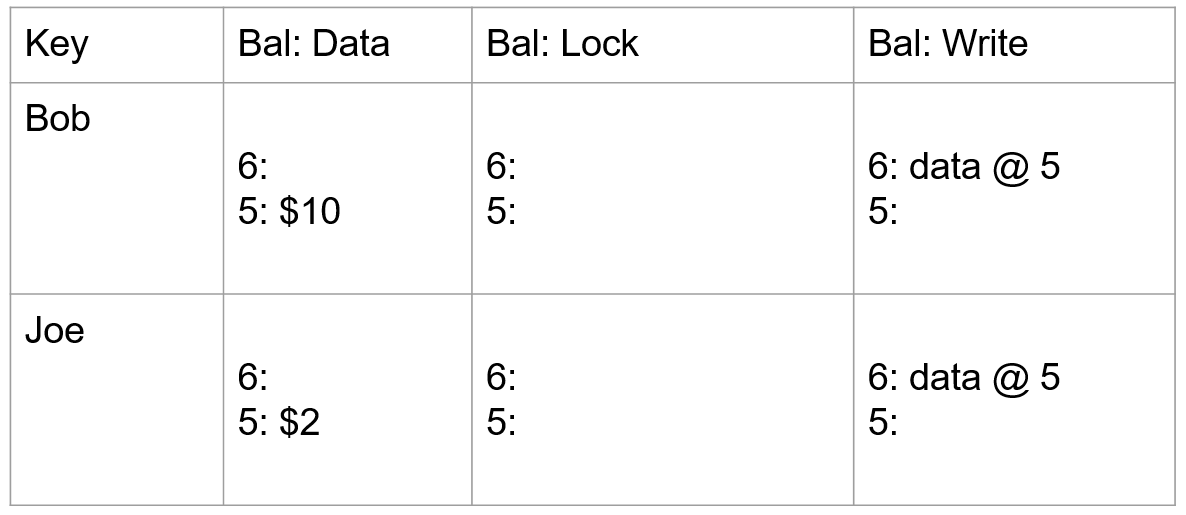
- 事务开始,获取 start_ts=7 作为当前事务的开始时间戳,将 Bob 行选为本事务的 primary,通过写入 lock 列锁定 Bob 的帐户,同时将数据 7:$3 写入到 data 列。
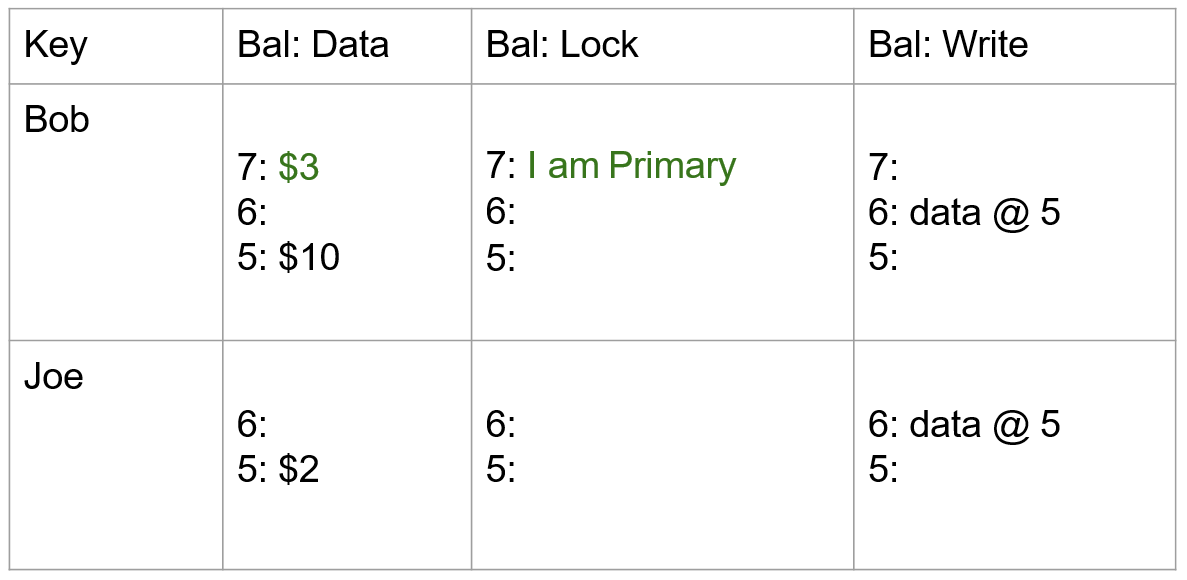
- 同样,使用 start_ts=7,将 Joe 改变后的余额写入到 data 列,当前操作作为 secondary,因此在 lock 列写入 7:Primary@Bob.bal(当失败时,能够快速定位到 primary 操作,并根据其状态异步清理)。
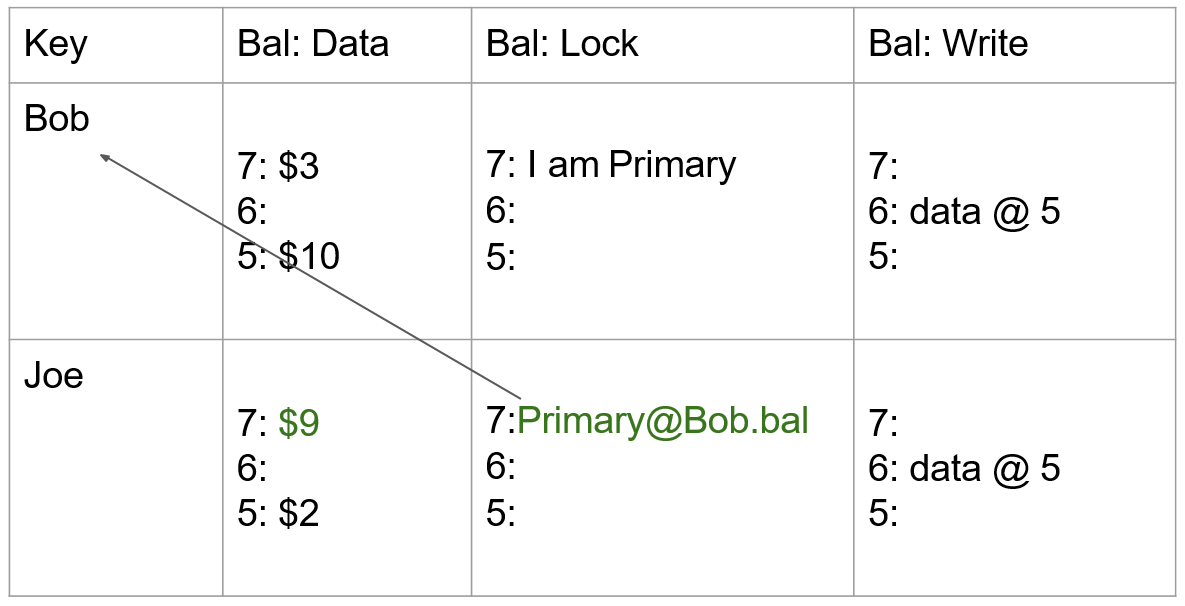
- 事务带着当前时间戳 commit_ts=8 进入 Commit 阶段:删除 primary 所在的 lock,并在 write 列中写入以提交时间戳作为版本号指向数据存储的一个指针 data@7。至此,读请求过来时将看到 Bob 的余额为 3。
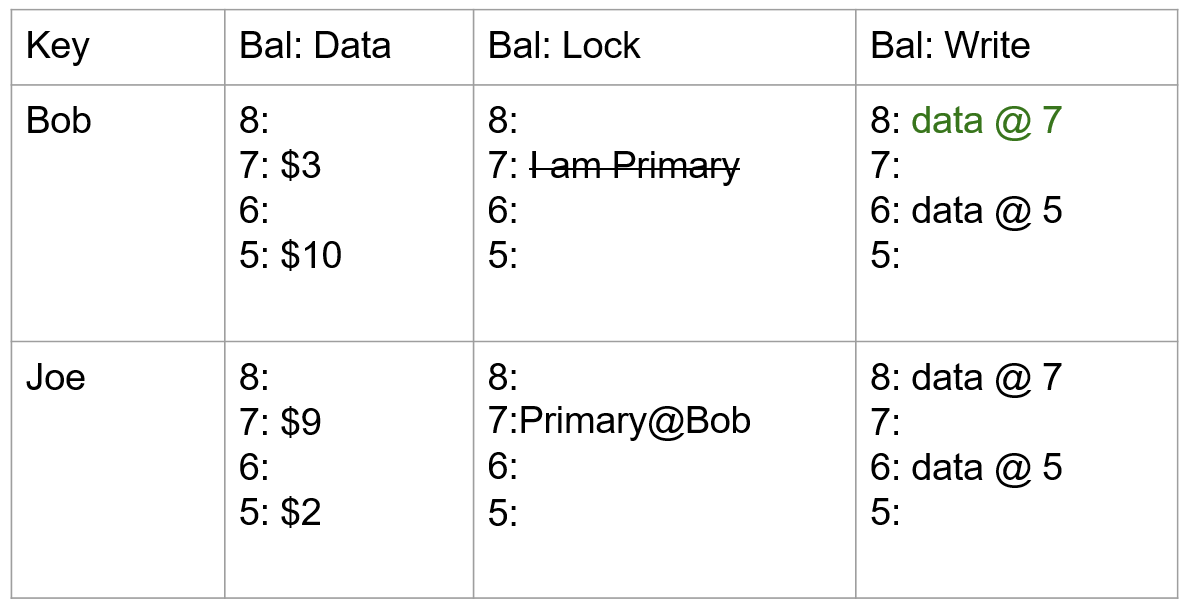
- 同样,使用 commit_ts=8,依次在 secondary 操作项中写入 write 列并清理锁。
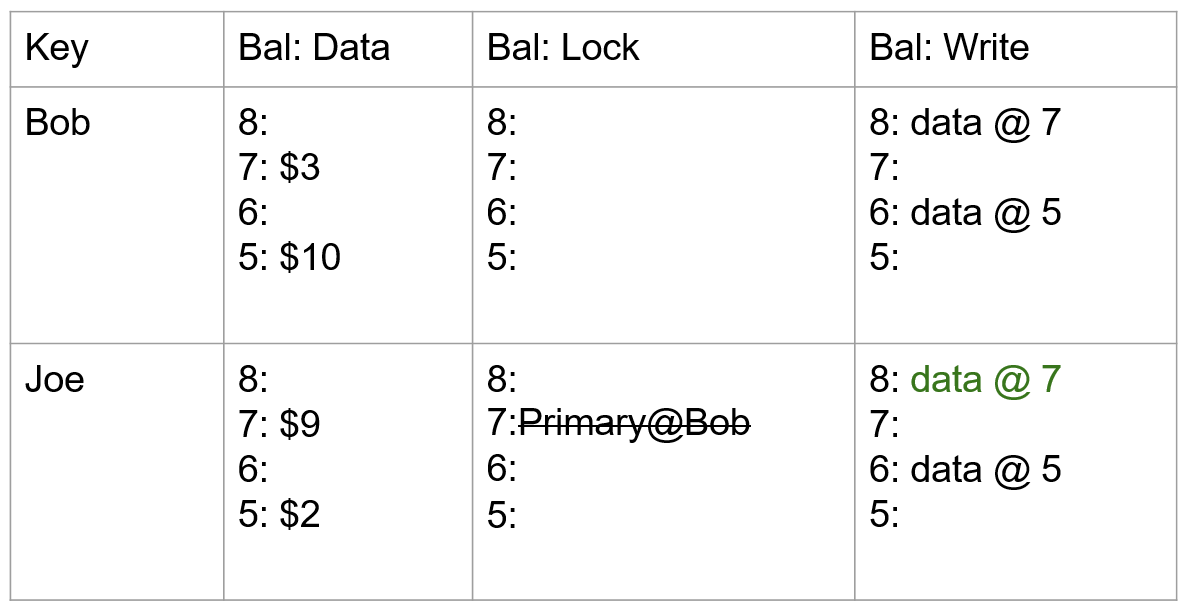
- 至此,整个当前 Percolator 事务已完成。
对比
相比 2PC 存在的问题,来看看 Percolator 事务模型有哪些改进。
单点故障
Percolator 通过日志和异步线程的方式弱化了这个问题。一是,Percolator 引入的异步线程可以在事务管理器宕机后,回滚各个分片上的事务,提供了善后手段,不会让分片上被占用的资源无法释放。二是,事务管理器可以用记录日志的方式使自身无状态化,日志通过共识算法同时保存在系统的多个节点上。这样,事务管理器宕机后,可以在其他节点启动新的事务管理器,基于日志恢复事务操作。数据不一致
2PC 的一致性问题主要缘自第二阶段,不能确保事务管理器与多个参与者的通讯始终正常。但在 Percolator 的第二阶段,事务管理器只需要与 primary 操作所在的一个节点通讯,这个 Commit 操作本身就是原子的。所以,事务的状态自然也是原子的,一致性问题被完美解决了。
Snapshot Isolation
传统关系型数据库中定义的隔离级别有4种(RU、RC、RR、S),而 Percolator 事务模型提供的隔离级别是快照隔离(Snapshot Isolation, SI),它也是与 MVCC 相辅相成的。SI的优点是:
- 对于读操作,保证能够从时间戳/版本号指定的稳定快照获取,不会发生幻读
- 对于写操作,保证在多个事务并发写同一条记录时,最多只有一个会提交成功
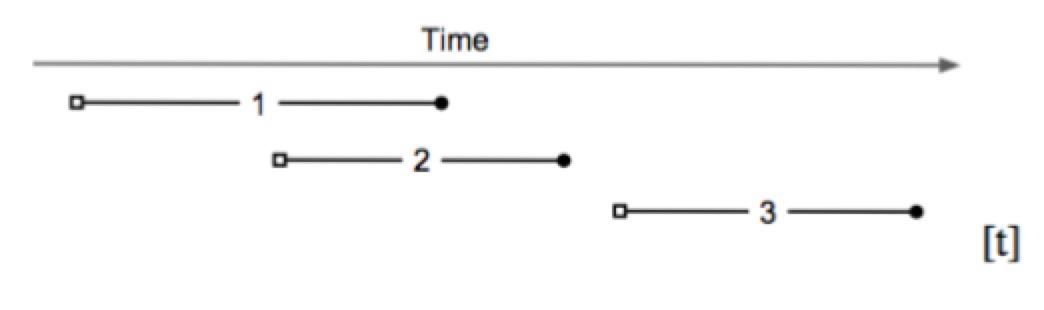
如图,基于快照隔离的事务,开始于 start timestamp(图内为小空格),结束于 commit timestamp(图内为小黑球)。本例包含以下信息:
- txn_2 不能看到 txn_1 的提交信息,因为 txn_2 的开始时间戳 start timestamp 小于 txn_1 的提交时间戳 commit timestamp
- txn_3 可以看到 txn_2 和 txn_1 的提交信息
- txn_1 和 txn_2 并发执行:如果它们对同一条记录进行写入,至少有一个会失败
参考
- Peng D, Dabek F, Inc G . “Large-scale Incremental Processing Using Distributed Transactions and Notifications” (2010).
Google Percolator