Vectorization vs. Compilation in Query Execution
当代 CPU 特性
超标量流水线与乱序执行
CPU指令的执行可以分为5个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
流水线:一套控制单元可以同时执行多条指令,不需要等到上一条指令执行完就可以执行下一条指令。
超标量:一个 CPU 核有多套控制单元,因此可以有多条 pipeline 并发执行。CPU 还会维护一个乱序执行的指令窗口,窗口中的无数据依赖的指令就可以被取来并发执行。并发指令越多越好,因为这样指令之间没有依赖,并发流水线的执行会更加的流畅。
分支预测
遇到 if/switch 这种判断跳转的指令时会产生分支预测,分支预测系统会决定流水线接下来是载入紧挨着判断指令的下一条指令,还是载入跳转到另一个地址的指令。如果 CPU 的预测是正确的,那么判断指令结果出来的那一刻,真正需要执行的指令已经执行到尾声了,这时候只需要继续执行即可;如果CPU的预测是错误的,那么会把执行到尾声的错误指令全部清空,恢复到从未执行过的状态,然后再执行正确的指令。
程序分支越少或者是分支预测成功率越高,对流水线的执行就越有利,因为如果预测失败了,是要丢弃当前 pipeline 的所有指令重新 flush,这个过程往往会消耗掉十几个 CPU 周期。
多级存储与数据预取
当数据在寄存器,cache 或者内存中,CPU 取数据的速度并不是在一个个数量级上的。CPU 取指令/数据的时候并不是直接从内存中取的,通常 CPU 和内存中会有多级缓存,分别为 L1,L2,L3 cache,其中 L1 cache 又可以分为 L1-data cache,L1-instruction cache。先从 cache 中取数据,若不存在,才访问内存。访问内存的时候会同时把访问数据相邻的一些数据一起加载进 cache 中。
预取指的是若数据存在线性访问的模式,CPU会主动把后续的内存块预先加载进cache中。
SIMD
单指令多数据流,对于数据密集型的程序来说,可能会需要对大量不同的数据进行相同的运算。SIMD 引入了一组大容量的寄存器,比如 128 位,256 位。可以将这多个数据按次序同时放到一个寄存器。同时,CPU 新增了处理这种大容量寄存器的指令,可以在一个指令周期内完成多个数据的运算。
早期解释执行模型
大多数的 query 解释器模型都是使用基于迭代器的火山模型,如下图所示。每个算子看成一个 iterator,iterator 会提供一个 next 方法,每个 next 方法只会产生一个 tuple,可以理解为一行数据。查询执行的时候,查询树自顶向下调用 next 接口,数据则自底向上被拉取处理,层层计算返回结果。所以火山模型属于 pull 模型。
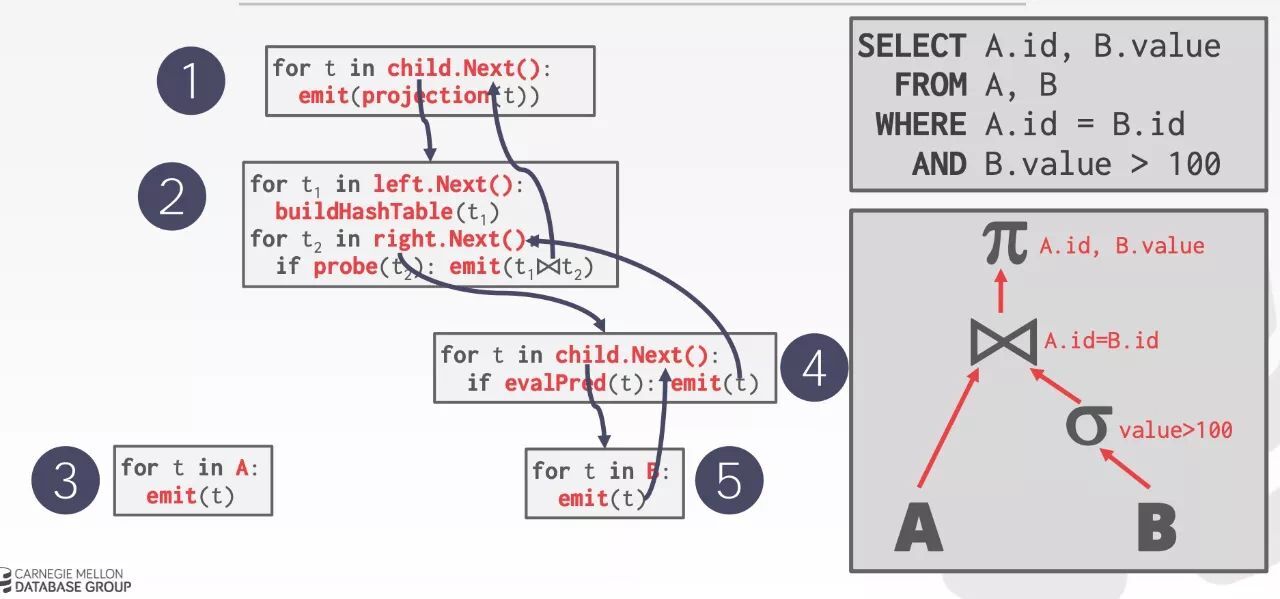
Volcano 模型简单灵活,且这种设计不用占用过多的内存。火山模型将更多的内存资源用于磁盘 IO 的缓存设计而没有优化 CPU 的执行效率,这在当时的硬件基础上是很自然的权衡。但是现在 CPU 的硬件环境与大数据场景下,性能表现却差强人意。主要有如下几点原因:
时间都花在了query plan上,而不是计算上
next 函数实现为虚函数,调用虚函数的时候要去查虚函数表,编译器无法对虚函数进行 inline 优化。同时会带来分支预测的开销,导致一次错误的 CPU 分支预测,需要多花费十几个 CPU 周期的开销。CPU cache利用率低
next 方法一次只返回一个元组,元组通常采用行存储,如果仅需访问其中某个字段但是每次都将整行数据填入 CPU cache,将导致那些不会被访问的字段也放在了 Cache 中,使得 cache 利用率非常低。
编译执行
编译执行指的是运行时期的代码生成生成技术。在执行过程中生成编译执行代码,避免过多的虚函数调用和解析执行,因为在执行之初我们是知道关系代数的 Schema 信息。在具备 Schema 信息的情况下,事先生成好的代码,可以有效减少很多执行分支预测开销。

上图右边的代码非常紧凑,有效消除了字段个数,字段大小,字段类型,对于数据量特别多的处理场景,可以大大减少CPU开销,提高性能。
编译执行以数据为中心,消灭了火山模型中的大量虚函数调用开销。甚至使大部分指令执行,可以直接从寄存器取数,极大提高了执行效率。
在 Java 中通过 JIT 来实现,在 C++ 中通过 LLVM 来实现 codegen,对于 OLAP 这种运行时间较长的 query 来说,通常编译的时间是可以忽略的。
向量化执行
向量可以理解为按列组织的一组数据,连续存储的一列数据,在内存中可以表示为一个向量。
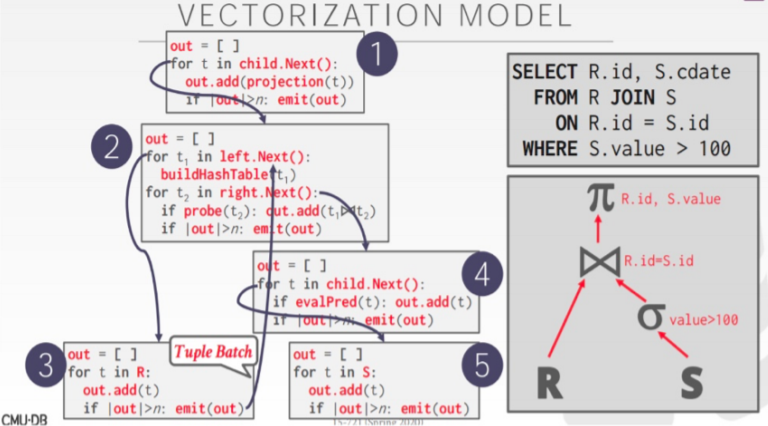
向量模型和火山模型的本质区别就在于,数据处理的基本单元不再是按行组织的 tuple,而是按列组织的多个向量,我们常说的一个 chunk 其实就是多个 vector 的集合,就是多个列的意思。
向量化执行好处是:由于每次 next 都是处理一批数据,那么大大减少了虚函数调用的次数,分支预测的成功概率会提升,减少了分支预测的开销,并且充分发挥 SIMD 指令并行计算的优势;还可以和列式存储有效结合在一起,减少数据额外转换的 overhead。
向量化和编译执行比较
向量化执行的主要访存开销在于像 join 这种算子的物化开销,物化就是从寄存器把数据读到内存中。而编译执行,tuple 可以一直留在寄存器中,一个 operator 处理完后,给另外一个 operator 继续处理。除非遇到不得不物化的情况。
向量化执行模型的循环较短,并发度高,可以同时有更多的指令等待取数。编译执行循环内部会包含多个 operator 的运算,这些有依赖关系的指令占据了大部分的乱序执行窗口,并发度低。
参考
- Sompolski, J. , M. Zukowski , and P. A. Boncz . “Vectorization vs. Compilation in Query Execution.” International Workshop on Data Management on New Hardware ACM, 2011.
- S. Wanderman-Milne and N. Li, “Runtime Code Generation in Cloudera Impala,” IEEE Data Eng. Bull., vol. 37, no. 1, pp. 31–37, 2014.
- 向量化与编译执行浅析
Vectorization vs. Compilation in Query Execution
https://hey-kong.github.io/2021/03/28/Vectorization-vs-Compilation-in-Query-Execution/