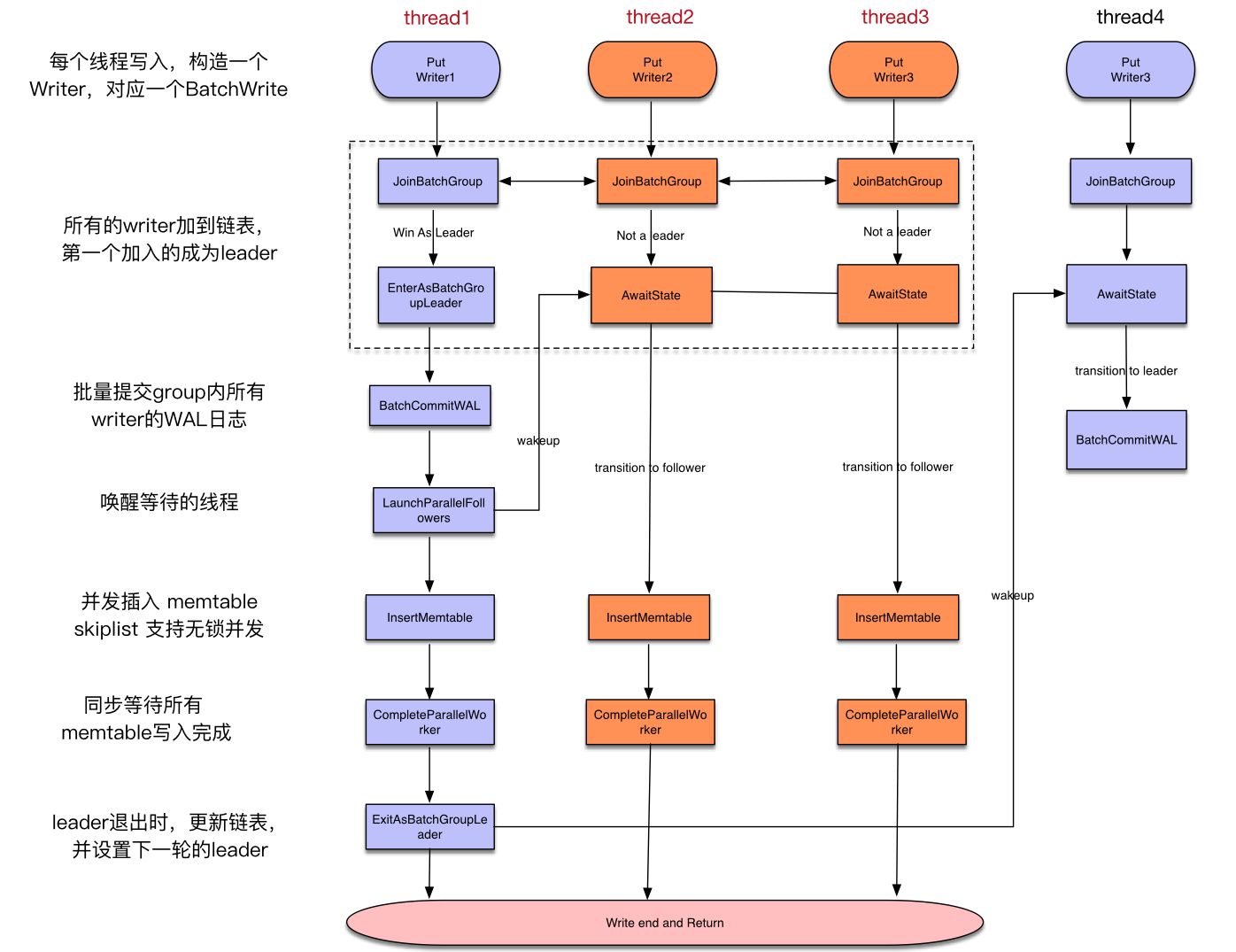
if (!linked_as_leader) { /** * Wait util: * 1) An existing leader pick us as the new leader when it finishes * 2) An existing leader pick us as its follewer and * 2.1) finishes the memtable writes on our behalf * 2.2) Or tell us to finish the memtable writes in pralallel * 3) (pipelined write) An existing leader pick us as its follower and * finish book-keeping and WAL write for us, enqueue us as pending * memtable writer, and * 3.1) we become memtable writer group leader, or * 3.2) an existing memtable writer group leader tell us to finish memtable * writes in parallel. */ TEST_SYNC_POINT_CALLBACK("WriteThread::JoinBatchGroup:BeganWaiting", w); AwaitState(w, STATE_GROUP_LEADER | STATE_MEMTABLE_WRITER_LEADER | STATE_PARALLEL_MEMTABLE_WRITER | STATE_COMPLETED, &jbg_ctx); TEST_SYNC_POINT_CALLBACK("WriteThread::JoinBatchGroup:DoneWaiting", w); } }
bool WriteThread::LinkOne(Writer* w, std::atomic<Writer*>* newest_writer) { assert(newest_writer != nullptr); assert(w->state == STATE_INIT); Writer* writers = newest_writer->load(std::memory_order_relaxed); while (true) { // If write stall in effect, and w->no_slowdown is not true, // block here until stall is cleared. If its true, thenreturn // immediately if (writers == &write_stall_dummy_) { if (w->no_slowdown) { w->status = Status::Incomplete("Write stall"); SetState(w, STATE_COMPLETED); returnfalse; } // Since no_slowdown is false, wait here to be notified of the write // stall clearing { MutexLock lock(&stall_mu_); writers = newest_writer->load(std::memory_order_relaxed); if (writers == &write_stall_dummy_) { stall_cv_.Wait(); // Load newest_writers_ again since it may have changed writers = newest_writer->load(std::memory_order_relaxed); continue; } } } w->link_older = writers; if (newest_writer->compare_exchange_weak(writers, w)) { return (writers == nullptr); } } }
// Allow the group to grow up to a maximum size, but if the // original write is small, limit the growth so we do not slow // down the small write too much. size_t max_size = max_write_batch_group_size_bytes; const uint64_t min_batch_size_bytes = max_write_batch_group_size_bytes / 8; if (size <= min_batch_size_bytes) { max_size = size + min_batch_size_bytes; }
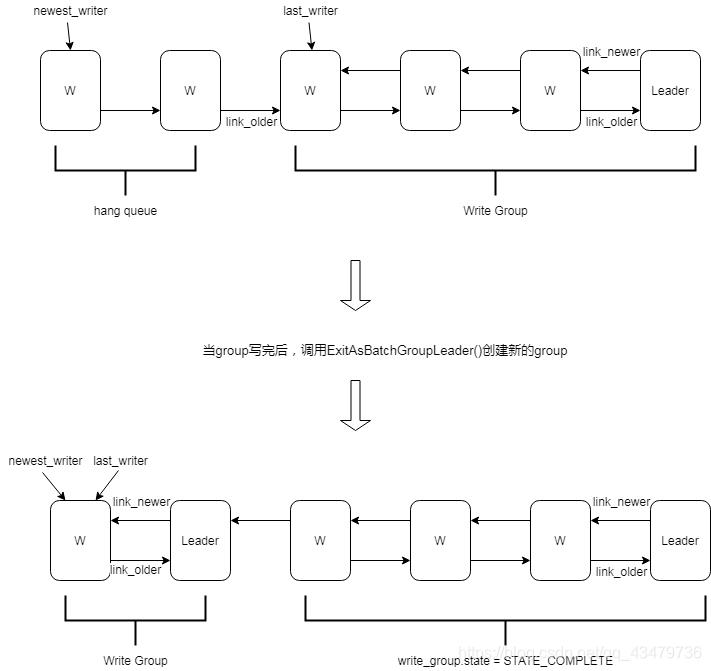
// This is safe regardless of any db mutex status of the caller. Previous // calls to ExitAsGroupLeader either didn't call CreateMissingNewerLinks // (they emptied the list and then we added ourself as leader) or had to // explicitly wake us up (the list was non-empty when we added ourself, // so we have already received our MarkJoined). CreateMissingNewerLinks(newest_writer); // Tricky. Iteration start (leader) is exclusive and finish // (newest_writer) is inclusive. Iteration goes from old to new. Writer* w = leader; while (w != newest_writer) { w = w->link_newer; if (w->sync && !leader->sync) { // Do not include a sync write into a batch handled by a non-sync write. break; } if (w->no_slowdown != leader->no_slowdown) { // Do not mix writes that are ok with delays with the ones that // request fail on delays. break; } if (w->disable_wal != leader->disable_wal) { // Do not mix writes that enable WAL with the ones whose // WAL disabled. break; } if (w->batch == nullptr) { // Do not include those writes with nullptr batch. Those are not writes, // those are something else. They want to be alone break; } if (w->callback != nullptr && !w->callback->AllowWriteBatching()) { // dont batch writes that don't want to be batched break; }
auto batch_size = WriteBatchInternal::ByteSize(w->batch); if (size + batch_size > max_size) { // Do not make batch too big break; }