gRPC 基础
gRPC 概览
gRPC 是由 Google 开发并开源的一种语言中立的 RPC 框架,当前支持 C、Java 和 Go 语言,其中 C 版本支持 C、C++、Node.js、C# 等。在 gRPC 的客户端应用可以像调用本地方法一样直接调用另一台不同的机器上的服务端的方法。
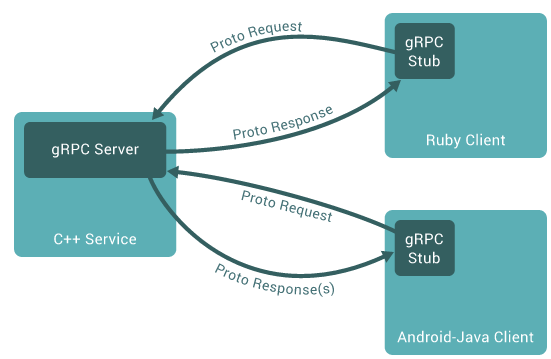
简单使用 gRPC 的步骤如下,以 Go 语言为例:
- 写好 proto 文件,用 protoc 生成.pb.go文件
- 服务端定义 Server,创建 Function 实现接口 -> net.Listen -> grpc.NewServer() -> pb.RegisterXXXServer(server, &Server{}) -> server.Serve(listener)
- 客户端 grpc.Dial,创建一个 gRPC 连接 -> pb.NewXXXClient(conn),创建 client -> context.WithTimeout,设置超时时间 -> client.Function,调用接口 -> 如果是流式传输则循环读取数据
gRPC 概念详解
流

Unary RPC
客户端发送一个请求给服务端,从服务端获取一个应答,就像一次普通的函数调用。
Server streaming RPC
客户端发送一个请求给服务端,可获取一个数据流用来读取一系列消息。客户端从返回的数据流里一直读取直到没有更多消息为止。
server 需要向流中发送消息,例如:
1 | for n := 0; n < 5; n++ { |
client 通过 grpc 调用获得的是一个流传输对象 stream,需要循环接收数据,例如:
1 | for { |
Client streaming RPC
客户端用提供的一个数据流写入并发送一系列消息给服务端。一旦客户端完成消息写入,就等待服务端读取这些消息并返回应答。
server 使用 stream.Recv() 来循环接收数据流,SendAndClose 表示服务器已经接收消息结束,并发生一个正确的响应给客户端,例如:
1 | for { |
client 发送数据完毕的时候需要调用 CloseAndRecv,例如:
1 | for i := 1; i <= 10; i++ { |
Bidirectional streaming RPC
两边都可以分别通过一个读写数据流来发送一系列消息。这两个数据流操作是相互独立的,所以客户端和服务端能按其希望的任意顺序读写,例如:服务端可以在写应答前等待所有的客户端消息,或者它可以先读一个消息再写一个消息,或者是读写相结合的其他方式。
server 在接收消息的同时发送消息,例如:
1 | for { |
client 需要有一个执行断开连接的标识 CloseSend(),而 server 不需要,因为服务端断开连接是隐式的,我们只需要退出循环即可断开连接,例如:
1 | for i := 1; i <= 10; i++ { |
同步
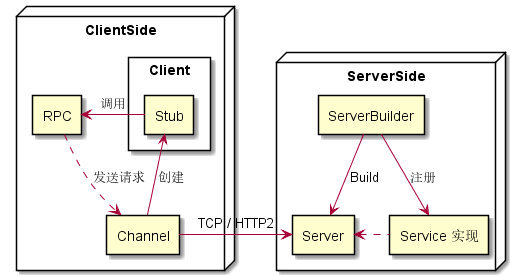
Channel 提供一个与特定 gRPC server 的主机和端口建立的连接。Stub 就是在 Channel 的基础上创建而成的,通过 Stub 可以真正的调用 RPC 请求。
基于 CQ 异步
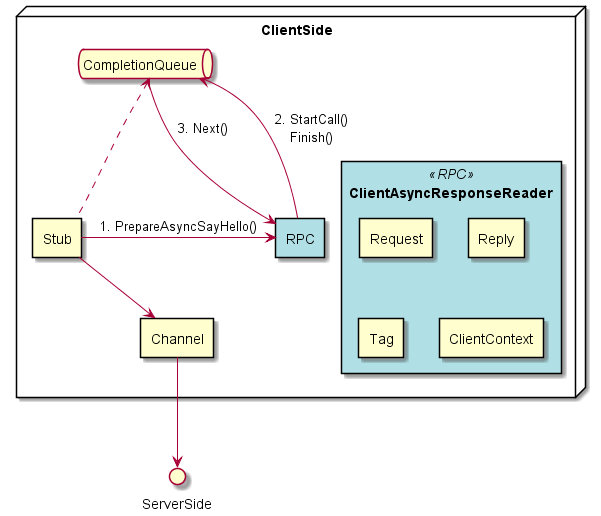
- CQ:异步操作完成的通知队列
- StartCall() + Finish():创建异步任务
- CQ.next():获取完成的异步操作
- Tag:标记异步动作的标识
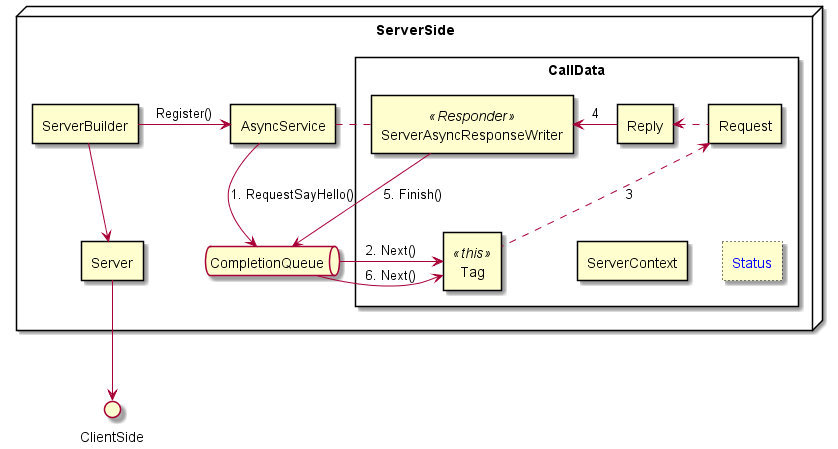
多个线程可以操作同一个CQ。CQ.next() 不仅可以接收到当前处理的请求的完成事件,还可以接收到其他请求的事件。假设第一个请求正在等待它的回复数据传输完成时,一个新的请求到达了,CQ.next() 可以获得新请求产生的事件,并开始并行处理新请求,而不用等待第一个请求的传输完成。
基于回调异步
在 client 端发送单个请求,在调用 Function 时,除了传入 Request、 Reply 的指针之外,还需要传入一个接收 Status 的回调函数。
在 server 端 Function 返回的不是状态,而是 ServerUnaryReactor 指针,通过 CallbackServerContext 获得 reactor,调用 reactor 的 Finish 函数处理返回状态。
上下文
- 在 client 端和 server 端之间传输一些自定义的 Metadata。
- 类似于 HTTP 头,控制调用配置,如压缩、鉴权、超时。
- 辅助可观测性,如 Trace ID。
gRPC 通信协议
gRPC 通信协议基于标准的 HTTP/2 设计,支持双向流、单 TCP 的多路复用(一个 HTTP 请求无需等待前一个 HTTP 请求返回结果就可以提前发起,多个请求可以共用同一个 HTTP 连接且互不影响)以及消息头压缩和服务端推送等特性,这些特性使得 gRPC 在移动端设备上更加省电和节省网络流量。
gRPC 序列化机制
Protocol Buffers 介绍
gRPC 序列化支持 Protocol Buffers。ProtoBuf 是一种轻便高效的数据结构序列化方法,保障了 gRPC 调用的高性能。它的优势在于:
- ProtoBuf 序列化后的体积要比 json、XML 小很多,序列化/反序列化的速度更快。
- 支持跨平台、多语言。
- 使用简单,因为它提供了一套编译工具,可以自动生成序列化、反序列化的样板代码。
但是,ProtoBuf 是二进制协议,编码后二进制数据流可读性差,调试麻烦。
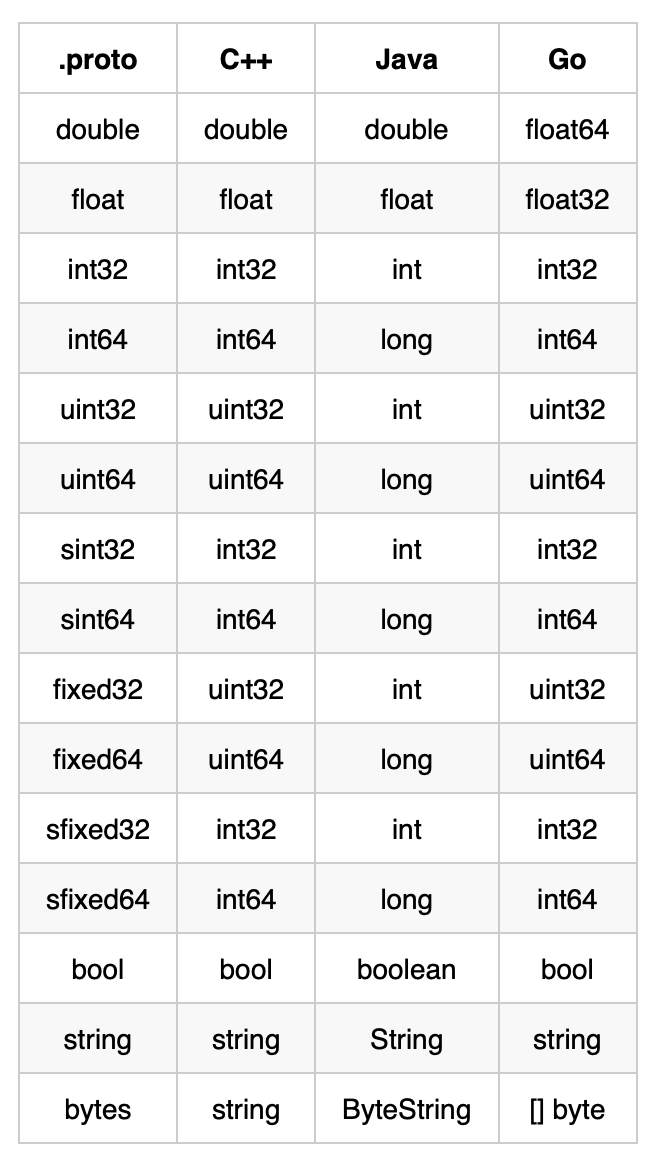
ProtoBuf 支持的标量值类型如下:
ProtoBuf 为什么快?
- 因为每个字段都用 tag+value 这种方式连续存储的,tag 是编号,一般只占用一个字节,value 是字段的值,这样就没有冗余字符。
- 另外,对于比较小的整数,ProtoBuf 中定义了 Varint 可变整型,可以不用 4 个字节去存。
- 如果 value 是字符串类型的,从 tag 当中无法了解到 value 具体有多长,ProtoBuf 会在 tag 与 value 之间添加一个 leg 字段去记录字符串的长度,这样就可以不做字符串匹配操作,解析速度非常快。
IDL 文件定义
按照 Protocol Buffers 的语法在 proto 文件中定义 RPC 请求和响应的数据结构,示例如下:
1 | syntax = "proto3"; |
其中,syntax proto3 表示使用 v3 版本的 Protocol Buffers,v3 和 v2 版本语法上有较多的变更, 使用的时候需要特别注意。go_package 表示生成代码的存放路径(包路径)。通过 message 关键字来定义数据结构,数据结构的语法为:
数据类型 字段名称 = Tag
message 是支持嵌套的,即 A message 引用 B message 作为自己的 field,它表示的就是对象聚合关系,即 A 对象聚合(引用)了 B 对象。
对于一些公共的数据结构,例如公共 Header,可以通过单独定义公共数据结构 proto 文件,然后导入的方式使用,示例如下:
import "other_protofile.proto";
导入也支持级联引用,即 a.proto 导入了 b.proto,b.proto 导入了 c.proto,则 a.proto 可以直接使用 c.proto 中定义的 message。