RDMA 基础
RDMA(Remote Direct Memory Access)指的是远程直接内存访问,这是一种通过网络在两个应用程序之间搬运缓冲区里的数据的方法。
- Remote:数据通过网络与远程机器间进行数据传输。
- Direct:没有内核的参与,有关发送传输的所有内容都卸载到网卡上。
- Memory:在用户空间虚拟内存与网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
- Access:send、receive、read、write、atomic 等操作。
RDMA 与传统的网络接口不同,因为它绕过了操作系统内核。这使得实现了 RDMA 的程序具有如下特点:
- 绝对的最低时延
- 最高的吞吐量
- 最小的 CPU 足迹 (也就是说,需要 CPU 参与的地方被最小化)
RDMA 工作原理
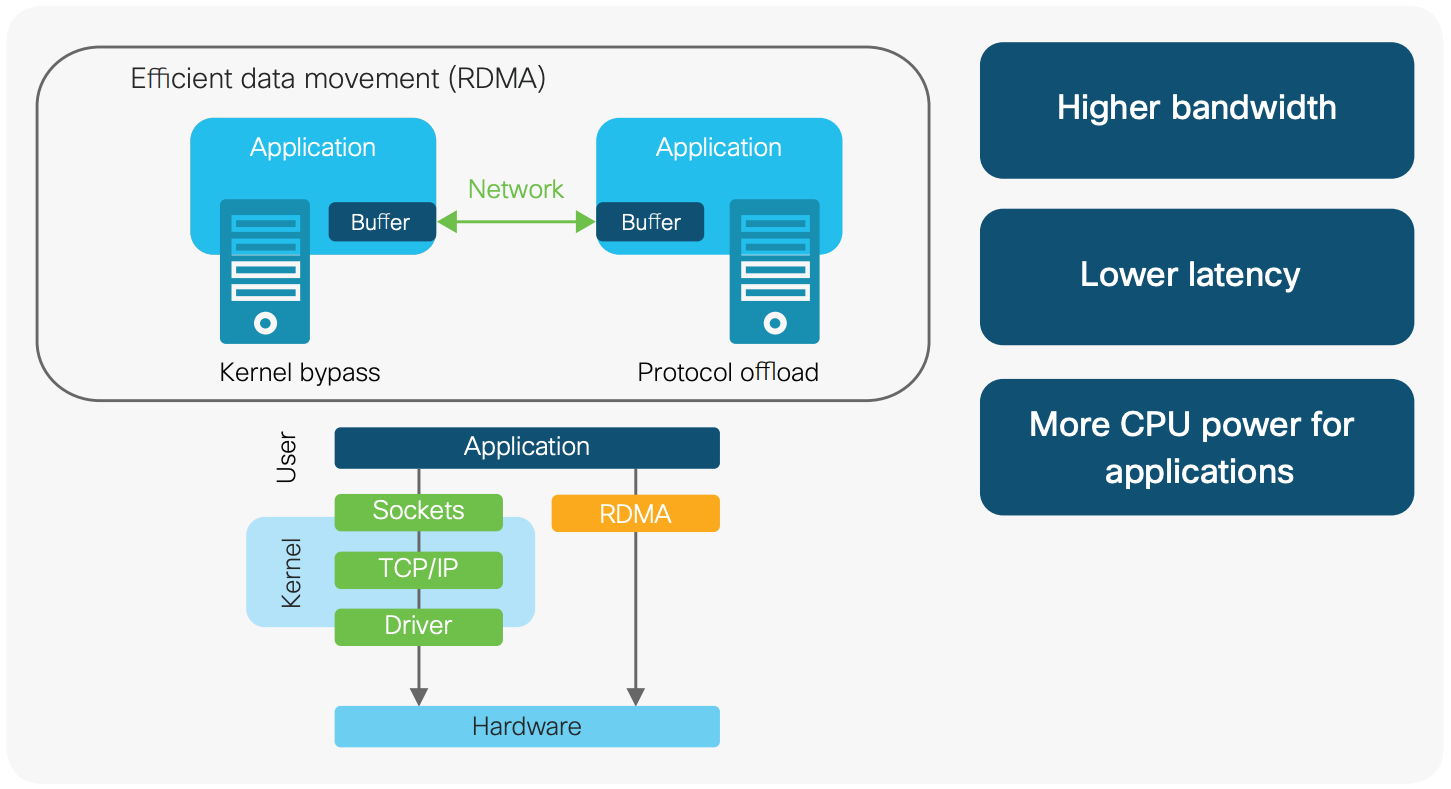
RDMA 通信过程中,发送和接收,读/写操作中,都是网卡直接和参与数据传输的已经注册过的内存区域直接进行数据传输,速度快,不需要 CPU 参与,RDMA 网卡接替了 CPU 的工作,节省下来的资源可以进行其它运算和服务。
RDMA 的工作过程如下:
- 当一个应用执行 RDMA 读或写请求时,不执行任何数据复制。在不需要任何内核内存参与的条件下,RDMA 请求从运行在用户空间中的应用中发送到本地网卡。
- 网卡读取缓冲的内容,并通过网络传送到远程网卡。
- 在网络上传输的 RDMA 信息包含目标机器虚拟内存地址和数据本身。请求完成可以完全在用户空间中处理(通过轮询用户空间的 RDMA 完成队列)。RDMA 操作使应用可以从一个远程应用的内存中读数据或向这个内存写数据。
因此,RDMA 可以简单理解为利用相关的硬件和网络技术,网卡可以直接读写远程服务器的内存,最终达到高带宽、低延迟和低资源利用率的效果。应用程序不需要参与数据传输过程,只需要指定内存读写地址,开启传输并等待传输完成即可。
RDMA 数据传输
RDMA Send/Recv
跟 TCP/IP 的 send/recv 是类似的,不同的是 RDMA 是基于消息的数据传输协议(而不是基于字节流的传输协议),所有数据包的组装都在 RDMA 硬件上完成的,也就是说 OSI 模型中的下面 4 层(传输层,网络层,数据链路层,物理层)都在 RDMA 硬件上完成。RDMA Read
RDMA 读操作本质上就是 Pull 操作,把远程系统内存里的数据拉回到本地系统的内存里。RDMA Write
RDMA 写操作本质上就是 Push 操作,把本地系统内存里的数据推送到远程系统的内存里。RDMA Write with Immediate Data(支持立即数的 RDMA 写操作)
支持立即数的 RDMA 写操作本质上就是给远程系统 Push 带外数据,这跟 TCP 里的带外数据是类似的。可选地,Immediate 4 字节值可以与数据缓冲器一起发送。该值作为接收通知的一部分呈现给接收者,并且不包含在数据缓冲器中。
RDMA 编程基础
使用 RDMA,我们需要有一张支持 RDMA 通信(即实现了 RDMA 引擎)的网卡。我们把这种卡称之为 HCA(Host Channel Adapter,主机通道适配器)。通过 PCIe(peripheral component interconnect express)总线, 适配器创建一个从 RDMA 引擎到应用程序内存的通道。一个好的 HCA 将执行的 RDMA 协议所需要的全部逻辑都在硬件上予以实现。这包括分组,重组以及流量控制和可靠性保证。因此,从应用程序的角度看,只负责处理所有缓冲区即可。
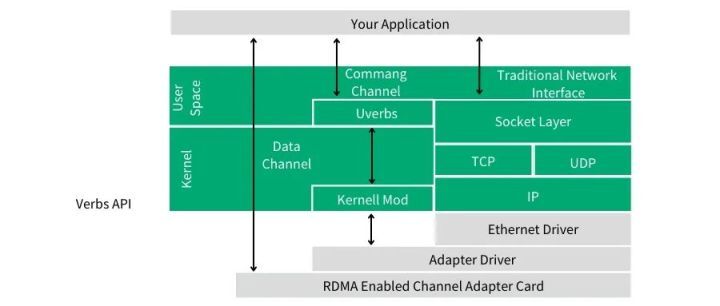
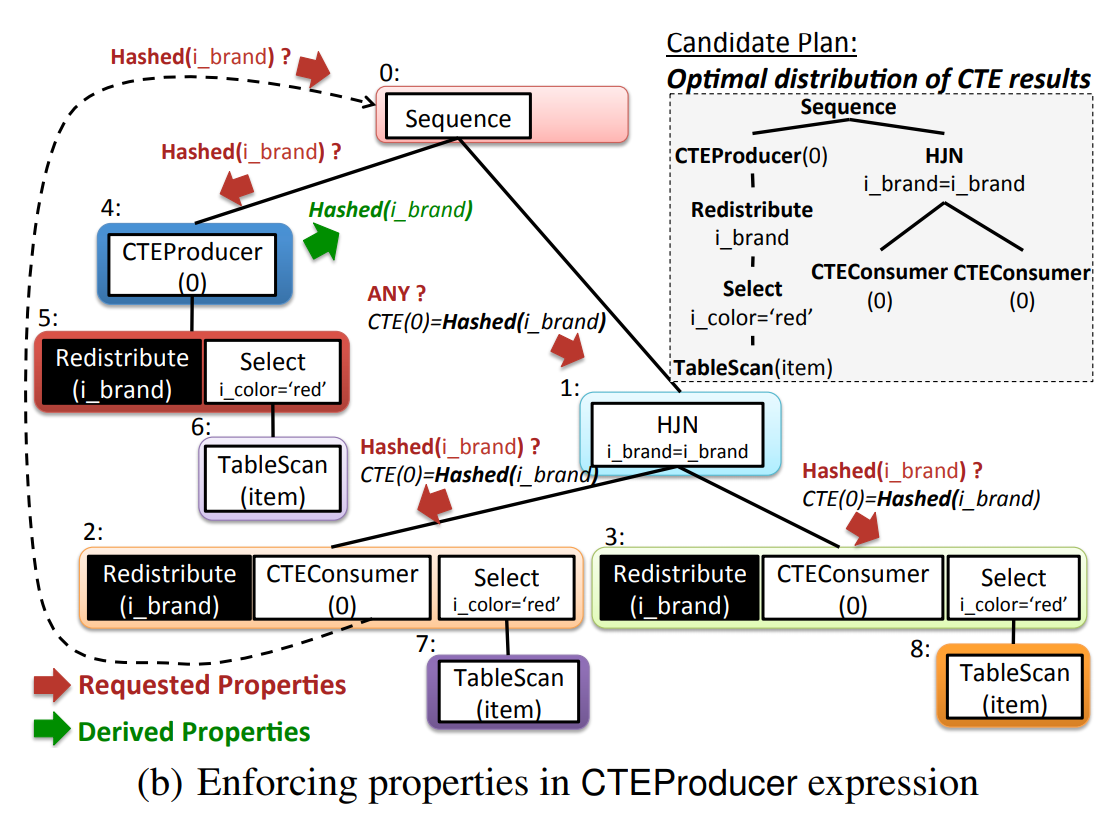
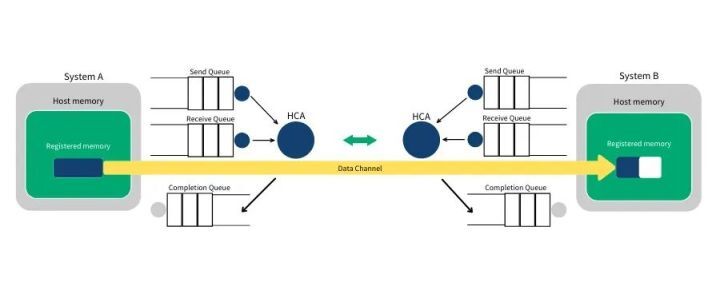
如上图所示,在 RDMA 编程中我们使用命令通道调用内核态驱动建立数据通道,该数据通道允许我们在搬运数据的时候完全绕过内核。一旦建立了这种数据通道,我们就能直接读写数据缓冲区。建立数据通道的 API 是一种称之为 verbs 的 API。verbs API 是由一个叫做 Open Fabrics Enterprise Distribution(OFED)的 Linux 开源项目维护的。
关键概念
RDMA 操作开始于操作内存。当你在操作内存的时候,就是告诉内核这段内存“名花有主”了,主人就是你的应用程序。于是,你告诉 HCA,就在这段内存上寻址,赶紧准备开辟一条从 HCA 卡到这段内存的通道。我们将这一动作称之为注册一个内存区域 MR(Memory Region)。注册时可以设置内存区域的读写权限(包括 local write,remote read,remote write,atomic,and bind)。调用 Verbs API ibv_reg_mr 即可实现注册 MR,该 API 返回 MR 的 remote 和 local key。local key 用于本地 HCA 访问本地的内存。remote key 是用于提供给远程 HCA 来访问本地的内存。一旦 MR 注册完毕,我们就可以使用这段内存来做任何 RDMA 操作。在下面的图中,我们可以看到注册的内存区域(MR)和被通信队列所使用的位于内存区域之内的缓冲区(buffer)。
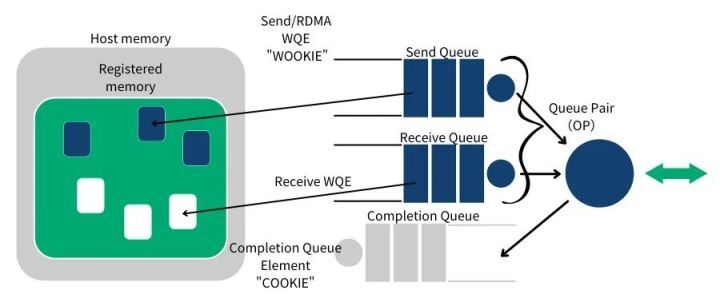
RDMA 通信基于三条队列 SQ(Send Queue),RQ(Receive Queue)和 CQ(Completion Queue)组成的集合。其中, 发送队列(SQ)和接收队列(RQ)负责调度工作,他们总是成对被创建,称之为队列对 QP(Queue Pair)。当放置在工作队列上的指令被完成的时候,完成队列(CQ)用来发送通知。
当用户把指令放置到工作队列的时候,就意味着告诉 HCA 那些缓冲区需要被发送或者用来接受数据。这些指令是一些小的结构体,称之为工作请求 WR(Work Request)或者工作队列元素 WQE(Work Queue Element)。一个 WQE 主要包含一个指向某个缓冲区的指针。一个放置在发送队列(SQ)里的 WQE 中包含一个指向待发送的消息的指针;一个放置在接受队列里的 WQE 里的指针指向一段缓冲区,该缓冲区用来存放待接受的消息。
RDMA 是一种异步传输机制。因此我们可以一次性在工作队列里放置好多个发送或接收 WQE。HCA 将尽可能快地按顺序处理这些 WQE。当一个 WQE 被处理了,那么数据就被搬运了。一旦传输完成,HCA 就创建一个状态为成功的完成队列元素 CQE(Completion Queue Element)并放置到完成队列(CQ)中去。如果由于某种原因传输失败,HCA 也创建一个状态为失败的 CQE 放置到(CQ)中去。
简单示例(Send/Recv)
第 1 步:系统 A 和 B 都创建了他们各自的 QP 和 CQ,并为即将进行的 RDMA 传输注册了相应的内存区域(MR)。系统 A 识别了一段缓冲区,该缓冲区的数据将被搬运到系统 B 上。系统 B 分配了一段空的缓冲区,用来存放来自系统 A 发送的数据。
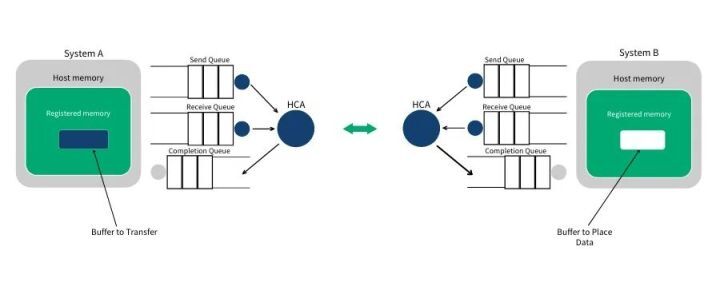
第 2 步:系统 B 创建一个 WQE 并放置到它的接收队列(RQ)中。这个 WQE 包含了一个指针,该指针指向的内存缓冲区用来存放接收到的数据。系统 A 也创建一个 WQE 并放置到它的发送队列(SQ)中去,该 WQE 中的指针执行一段内存缓冲区,该缓冲区的数据将要被传送。
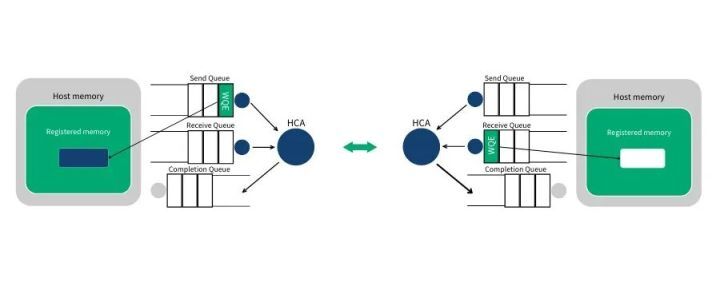
第 3 步:系统 A 上的 HCA 总是在硬件上干活,看看发送队列里有没有 WQE。HCA 将消费掉来自系统 A 的 WQE,然后将内存区域里的数据变成数据流发送给系统 B。当数据流开始到达系统 B 的时候,系统 B 上的 HCA 就消费来自系统 B 的 WQE,然后将数据放到该放的缓冲区上去。在高速通道上传输的数据流完全绕过了操作系统内核。
注:WQE 上的箭头表示指向用户空间内存的指针(地址)。receive/send 模式下,通信双方需要事先准备自己的 WQE(WorkQueue),HCA 完成后会写(CQ)。
第 4 步:当数据搬运完成的时候,HCA 会创建一个 CQE。这个 CQE 被放置到完成队列(CQ)中,表明数据传输已经完成。HCA 每消费掉一个 WQE,都会生成一个 CQE。因此,在系统 A 的完成队列中放置一个 CQE,意味着对应的 WQE 的发送操作已经完成。同理,在系统 B 的完成队列中也会放置一个 CQE,表明对应的 WQE 的接收操作已经完成。如果发生错误,HCA 依然会创建一个 CQE。在 CQE 中,包含了一个用来记录传输状态的字段。
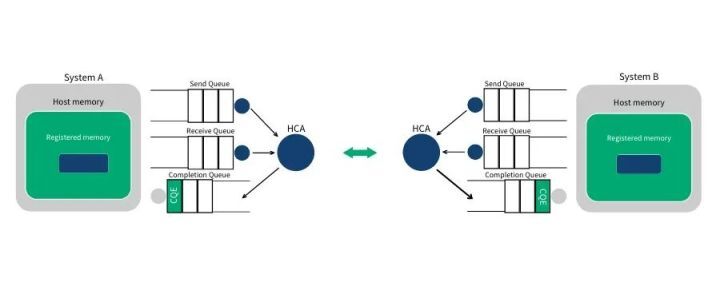
在 IB 或 RoCE 中,传送一个小缓冲区里的数据耗费的总时间大约在 1.3µs。通过同时创建很多 WQE, 就能在 1 秒内传输存放在数百万个缓冲区里的数据。
RDMA 操作细节
在 RDMA 传输中,Send/Recv 是双边操作,即需要通信双方的参与,并且 Recv 要先于 Send 执行,这样对方才能发送数据,当然如果对方不需要发送数据,可以不执行 Recv 操作,因此该过程和传统通信相似,区别在于 RDMA 的零拷贝网络技术和内核旁路,延迟低,多用于传输短的控制消息。
Write/Read 是单边操作,顾名思义,读/写操作是一方在执行,在实际的通信过程中,Write/Read 操作是由客户端来执行的,而服务器端不需要执行任何操作。RDMA Write 操作中,由客户端把数据从本地 buffer 中直接 push 到远程 QP 的虚拟空间的连续内存块中(物理内存不一定连续),因此需要知道目的地址(remote addr)和访问权限(remote key)。RDMA Read 操作中,是客户端直接到远程的 QP 的虚拟空间的连续内存块中获取数据 pull 到本地目的 buffer 中,因此需要远程 QP 的内存地址和访问权限。单边操作多用于批量数据传输。
可以看出,在单边操作过程中,客户端需要知道远程 QP 的 remote addr 和 remote key,而这两个信息是可以通过 Send/Recv 操作来交换的。
RDMA 单边操作(RDMA READ/WRITE)
READ 和 WRITE 是单边操作,只需要本端明确信息的源和目的地址,远端应用不必感知此次通信,数据的读或写都通过 RDMA 在网卡与应用 Buffer 之间完成,再由远端网卡封装成消息返回到本端。
对于单边操作,以存储网络环境下的存储为例,READ 流程如下:
- 首先 A、B 建立连接,QP 已经创建并且初始化。
- 数据被存档在 B 的 buffer 地址 VB,注意 VB 应该提前注册到 B 的网卡(并且它是一个 memory region),并拿到返回的 remote key,相当于 RDMA 操作这块 buffer 的权限。
- B 把数据地址 VB,key 封装到专用的报文传送到 A,这相当于 B 把数据 buffer 的操作权交给了 A。同时 B 在它的 WQ 中注册进一个 WR,以用于接收数据传输的 A 返回的状态。
- A 在收到 B 的送过来的数据 VB 和 remote key 后,网卡会把它们连同自身存储地址 VA 到封装 RDMA READ 请求,将这个消息请求发送给 B,这个过程 A、B 两端不需要任何软件参与,就可以将 B 的数据存储到 A 的 VA 虚拟地址。
- A 在存储完成后,会向 B 返回整个数据传输的状态信息。
WRITE 流程与 READ 类似。单边操作传输方式是 RDMA 与传统网络传输的最大不同,只需提供直接访问远程的虚拟地址,无须远程应用参与其中,这种方式适用于批量数据传输。
RDMA 双边操作(RDMA SEND/RECEIVE)
RDMA 中 SEND/RECEIVE 是双边操作,即必须要远端的应用感知参与才能完成收发。在实际中,SEND/RECEIVE 多用于连接控制类报文,而数据报文多是通过 READ/WRITE 来完成的。
对于双边操作为例,主机 A 向主机 B(下面简称 A、B)发送数据的流程如下:
- 首先,A 和 B 都要创建并初始化好各自的 QP,CQ。
- A 和 B 分别向自己的 WQ 中注册 WQE,对于 A,WQ = SQ,WQE 描述指向一个等到被发送的数据;对于 B,WQ = RQ,WQE 描述指向一块用于存储数据的 Buffer。
- A 的网卡异步调度轮到 A 的 WQE,解析到这是一个 SEND 消息,从 buffer 中直接向 B 发出数据。数据流到达 B 的网卡后,B 的 WQE 被消耗,并把数据直接存储到 WQE 指向的存储位置。
- A、B 通信完成后,A 的 CQ 中会产生一个完成消息 CQE 表示发送完成。与此同时,B 的 CQ 中也会产生一个完成消息表示接收完成。每个 WQ 中 WQE 的处理完成都会产生一个 CQE。
双边操作与传统网络的底层 Buffer Pool 类似,收发双方的参与过程并无差别,区别在零拷贝、kernel bypass,实际上对于 RDMA,这是一种复杂的消息传输模式,多用于传输短的控制消息。