RocksDB WriteImpl 流程
本文对 RocksDB 6.7.3 版本的 WriteImpl 流程进行分析。
概述
RocksDB 写入实现主要在 DBImpl::WriteImpl 中,过程主要分为以下三步:
- 把 WriteBatch 加入队列,多个 WriteBatch 成为一个 WriteGroup
- 将该 WriteGroup 所有的记录对应的日志写到 WAL 文件中
- 将该 WriteGroup 所有的 WriteBatch 中的一条或者多条记录写到内存中的 Memtable 中
其中,每个 WriteBatch 代表一个事务的提交,可以包含多条操作,可以通过调用 WriteBatch::Put/Delete 等操作将对应多条的 key/value 记录加入 WriteBatch 中。
源码分析
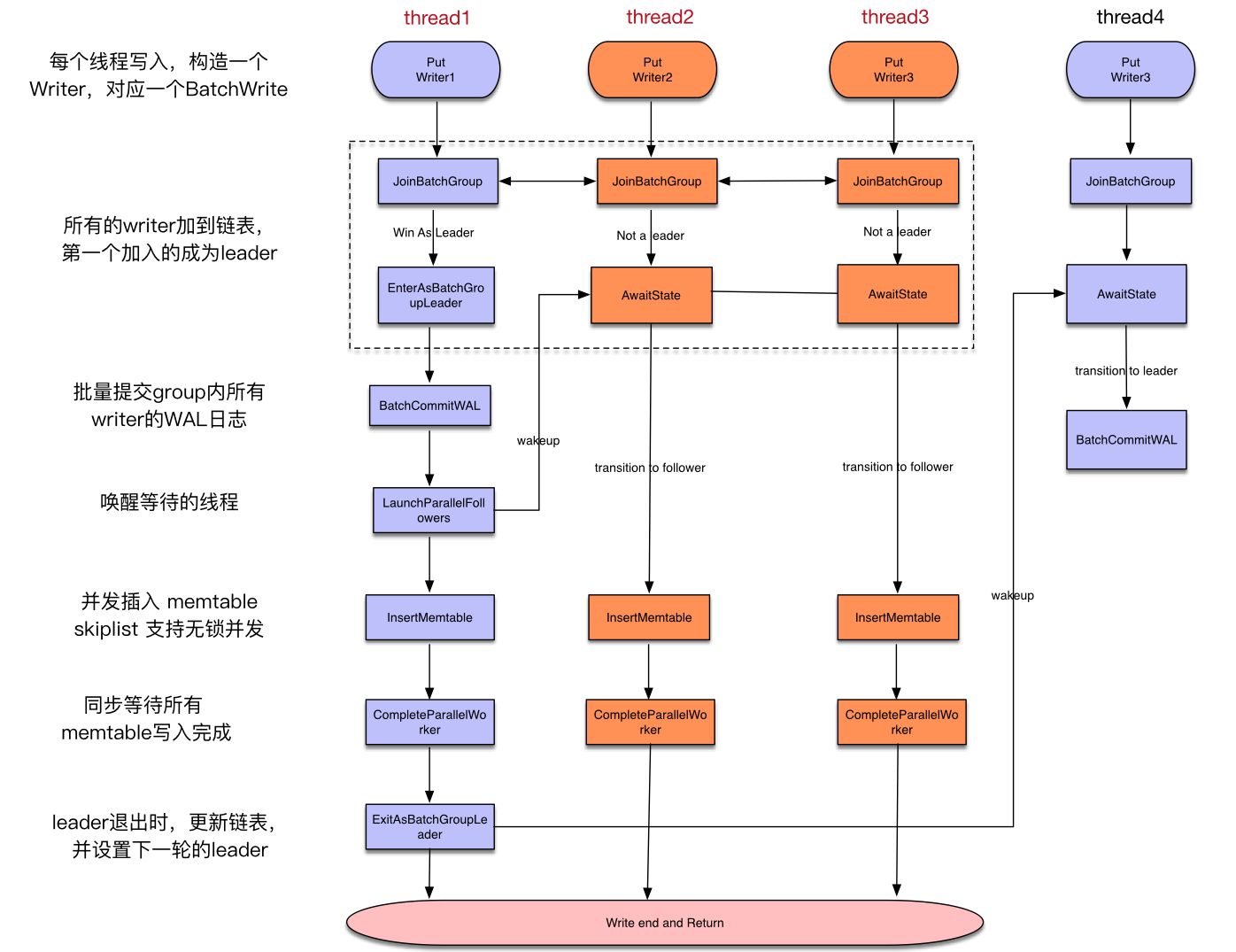
WriteThread::JoinBatchGroup
1 | static WriteThread::AdaptationContext jbg_ctx("JoinBatchGroup"); |
每个事务提交请求都会生成一个 WriteBatch 对象,进入 WriteImpl 函数后各自的线程首先调用 JoinBatchGroup 来加入到队列。该队列主要核心的实现在于 LinkOne 函数,通过 CAS 无锁将多个线程的请求组成请求链表:
1 | bool WriteThread::LinkOne(Writer* w, std::atomic<Writer*>* newest_writer) { |
write_group 链表结构如下:
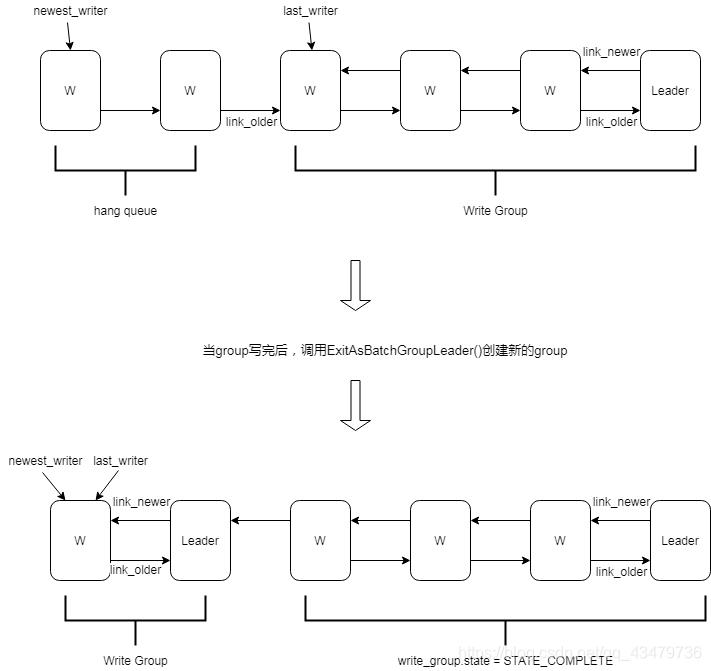
每个 writer 在头部插入,插入时如果发现 link_older 为空,则此 writer 成为 write_group 的 Leader(即链表尾为 Leader)。
在 JoinBatchGroup 中,如果 writer 不是 Leader(在后文把不是 Leader 的 writer 称为 Follower),则会调用 AwaitState 等待被唤醒。
PS:由于条件锁 Context Switches 代价高,Rocksdb 在 AwaitState 也做了优化,将 pthread_cond_wait 拆成 3 步来做,本文不对该优化进行详细描述。
WriteImpl 写日志
1 | if (w.state == WriteThread::STATE_GROUP_LEADER) { |
成为 Leader 的 writer,负责批量写入 WAL。在写 WAL 前,首先调用 EnterAsBatchGroupLeader 函数:
1 | size_t WriteThread::EnterAsBatchGroupLeader(Writer* leader, |
在这里,通过 CreateMissingNewerLinks 函数来生成一个双向链表,使得可以从 Leader 开始顺序写。创建完成反向写请求链表之后,则开始计算有多少个写请求可以批量的进行,同时更新 write_group 中的批量写尺寸以及个数等信息,EnterAsBatchGroupLeader 取队列时会把此刻所有的 writer 一次性全取完。
该操作完成之后,则进入写 WAL 的流程了。调用 WriteToWAL,在 MergeBatch 函数中,将根据 write_group 生成一个 merged_batch,该 merged_batch 中记录着应当被写入 WAL 的内容。接着就通过 WriteToWAL 将 merged_batch 写入 WAL 中,这里会根据是否设置了 sync 来决定是否对 WAL 进行落盘操作。
PS:这里有一个优化点,在生成 merged_batch 的时候,假设该写请求的尺寸为一并且该请求需要写 WAL,则 merged_batch 直接复用了该写请求;反之则会复用一个 tmp_batch_ 对象避免频繁的生成 WriteBatch 对象。在写完 WAL 之后,假设复用了 tmp_batch_,则会清空该对象。
最后,调用 ExitAsBatchGroupLeader,该函数会决定该 Leader 是否为 STATE_MEMTABLE_WRITER_LEADER(MEMTABLE_WRITER_LEADER数量 <= GROUP_LEADER数量),从而进行写 Memtable 流程。
WriteImpl 写 Memtable
1 | WriteThread::WriteGroup memtable_write_group; |
RocksDB 有一个 allow_concurrent_memtable_write 的配置项,开启后可以并发写 memtable(memtable 能设置并发写,但是 WAL 文件不能,因为 WAL 是一个追加写的文件,多个 writer 必须要串行化),所以接下来分为串行写和并行写来进行分析。
串行写 Memtable
Leader 调用 InsertInto,对 write_group 进行遍历,将 Leader 和 Follower 的 WriteBatch 写入。之后调用 ExitAsMemTableWriter,把所有 Follower 的状态设置为 STATE_COMPLETED,将它们唤醒,最后再把 Leader 的状态设置为 STATE_COMPLETED。
并行写 Memtable
调用 LaunchParallelMemTableWriters,遍历 write_group 把 Leader 和 Follower 的状态都设置为 STATE_PARALLEL_MEMTABLE_WRITER,将等待的线程唤醒。最后所有 writer 通过调用 InsertInto 来将 WriteBatch 写入 MemTable 中。writer 完成了 MemTable 的写操作之后,都会调用 CompleteParallelMemTableWriter 函数。该函数会将该 write_group 中运行的任务数减一,当运行中的任务数为零的时候就代表了所有的线程都完成了操作,调用 ExitAsMemTableWriter 把 Leader 的状态设置为 STATE_COMPLETED,反之则会进入等待状态,等待当前其他的写任务完成。
无论是串行写还是并行写,写入 MemTable 完成之后,还有一项工作,就是在取队列时获取 newest_writer_ 和当前时间点处,可能又有很多的写请求产生了,所以批量任务中最后一个完成的线程必须负责重新指定 Leader 给堆积写请求链表的尾部,让其接过 Leader 角色继续进行批量提交。可以看到,串行写和并行写最后都会调用 ExitAsMemTableWriter,正是在该函数中完成了该项工作。
PS:在高并发场景下,Follow 调用 AwaitState 的平均等待时延差不多是写 WAL 时延的两倍。因为获取 newest_writer_ 后,可能又来了许多写请求,这些写请求先要等待此时的 Leader 完成写流程,还要等待下个 Leader,也就是和这些写请求是同一个 write_group 的 Leader 完成写 WAL 才能被唤醒。
回顾