TiDB 架构
TiDB是支持MySQL语法的开源分布式混合事务/分析处理(HTAP)数据库。TiDB 可以提供水平可扩展性、强一致性和高可用性。它主要由 PingCAP 公司开发和支持,并在 Apache 2.0 下授权。TiDB 从 Google 的 Spanner 和 F1 论文中汲取了最初的设计灵感。
HTAP 是 Hybrid Transactional / Analytical Processing 的缩写。这个词汇在 2014 年由 Gartner 提出。传统意义上,数据库往往专为交易或者分析场景设计,因而数据平台往往需要被切分为 TP 和 AP 两个部分,而数据需要从交易库复制到分析型数据库以便快速响应分析查询。而新型的 HTAP 数据库则可以同时承担交易和分析两种智能,这大大简化了数据平台的建设,也能让用户使用更新鲜的数据进行分析。作为一款优秀的 HTAP 数据数据库,TiDB 除了优异的交易处理能力,也具备了良好的分析能力。
TiDB在整体架构基本是参考 Google Spanner 和 F1 的设计,上分两层为 TiDB 和 TiKV。 TiDB 对应的是 Google F1,是一层无状态的 SQL Layer,兼容绝大多数 MySQL 语法,对外暴露 MySQL 网络协议,负责解析用户的 SQL 语句,生成分布式的 Query Plan,翻译成底层 Key Value 操作发送给 TiKV,TiKV 是真正的存储数据的地方,对应的是 Google Spanner,是一个分布式 Key Value 数据库,支持弹性水平扩展,自动的灾难恢复和故障转移(高可用),以及 ACID 跨行事务。值得一提的是 TiKV 并不像 HBase 或者 BigTable 那样依赖底层的分布式文件系统,在性能和灵活性上能更好,这个对于在线业务来说是非常重要。
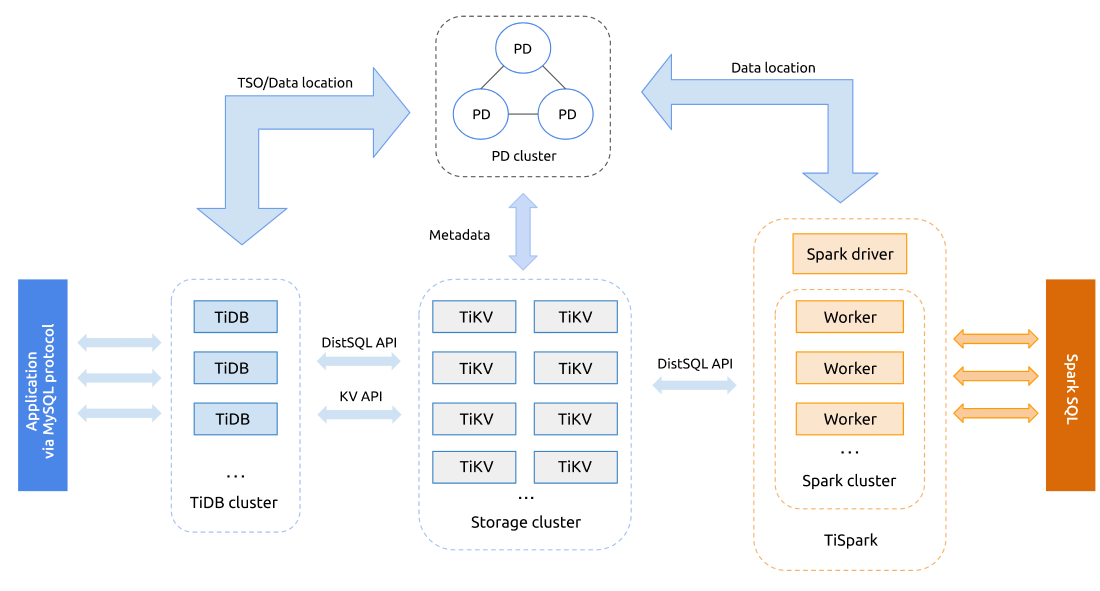
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
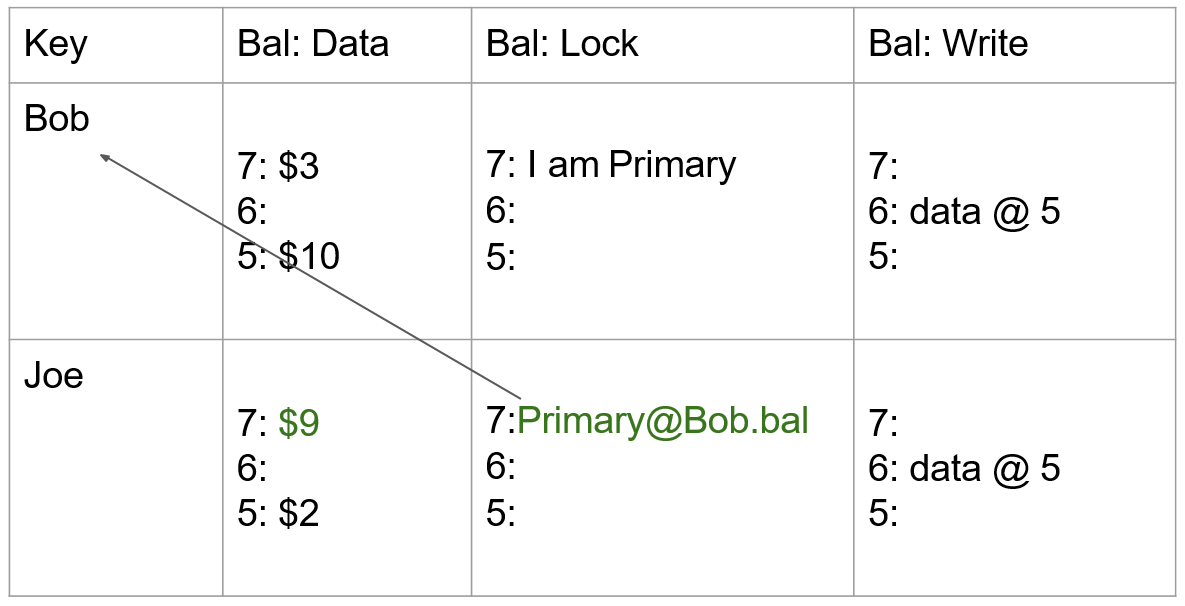
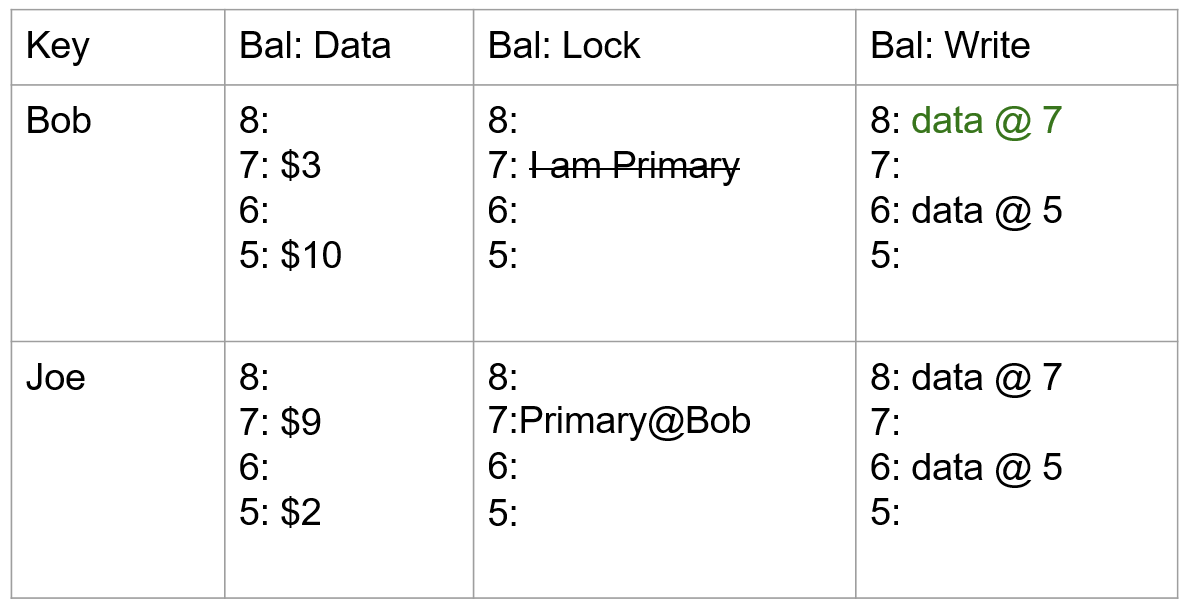
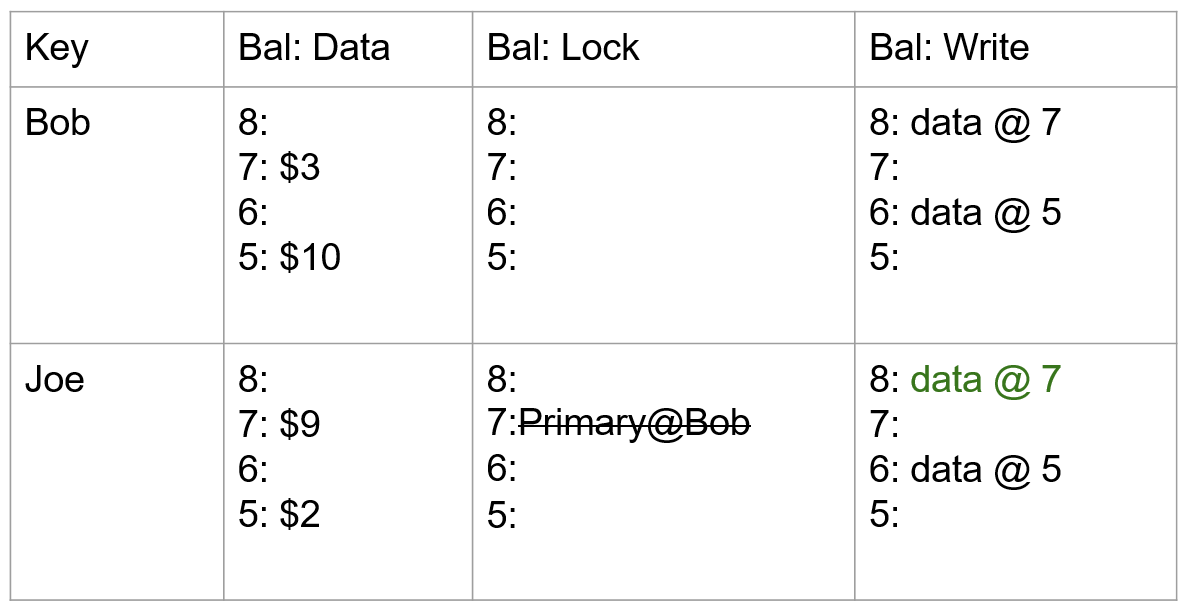
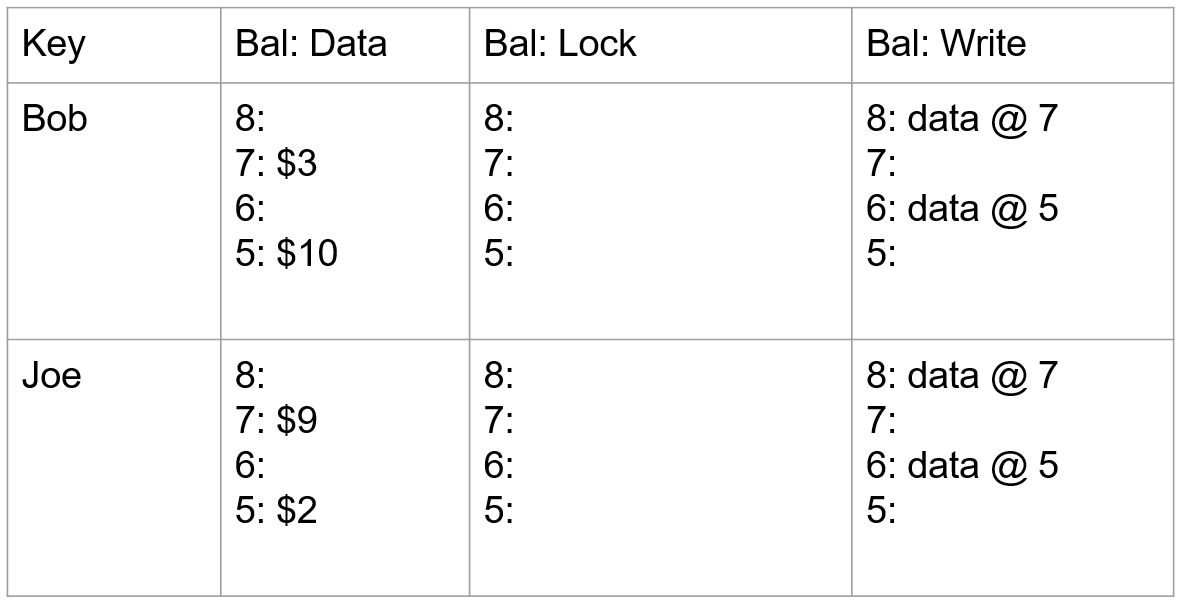
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
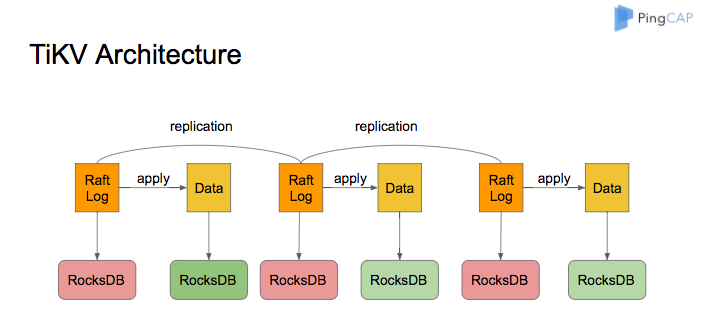
TiKV 基于 RocksDB,采用了 Raft 协议来实现分布式的一致性。TiKV 的系统架构如下图所示:
优点:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
- 智能的行列混合模式,TiDB 可经由优化器自主选择行列。这套选择的逻辑与选择索引类似:优化器根据统计信息估算读取数据的规模,并对比选择列存与行存访问开销,做出最优选择
缺点:
- 虽然兼容MySQL,但是不支持存储过程,触发器,自定义函数,窗口功能有限
- 不适用数据量小的场景,专门为大数据量设计