(gdb) break strings_not_equal Breakpoint 1 at 0x190f (gdb) run Starting program: /mnt/c/ubuntu/bomb65/bomb Welcome to my fiendish little bomb. You have 6 phases with which to blow yourself up. Have a nice day! test
Breakpoint 1, 0x000000000800190f in strings_not_equal () (gdb) p (char*)$rdi $1 = 0x80056a0 <input_strings> "test" (gdb) p (char*)$rsi $2 = 0x8003150 "I am just a renegade hockey mom."
def func4(a, c, d): if d < c: b = (d + c + 1) / 2 else: b = (d + c) / 2 if b < a: return func4(a, b+1, d)*2 + 1 if b > a: return func4(a, c, b-1)*2 else: return 0
hey-kong@LAPTOP-9010T96A:/mnt/c/ubuntu/csapp/bomb65$ ./bomb Welcome to my fiendish little bomb. You have 6 phases with which to blow yourself up. Have a nice day! I am just a renegade hockey mom. Phase 1 defused. How about the next one? 0 1 1 2 3 5 That's number 2. Keep going! 1 171 Halfway there! 13 3 So you got that one. Try this one. 5 115 Good work! On to the next... 3 1 2 6 5 4 Congratulations! You've defused the bomb!
row_cache_key.TrimAppend(prefix_size, user_key.data(), user_key.size()); if (auto row_handle = ioptions_.row_cache->Lookup(row_cache_key.GetUserKey())) { // Cleanable routine to release the cache entry Cleanable value_pinner; auto release_cache_entry_func = [](void* cache_to_clean, void* cache_handle) { ((Cache*)cache_to_clean)->Release((Cache::Handle*)cache_handle); }; auto found_row_cache_entry = static_cast<const std::string*>(ioptions_.row_cache->Value(row_handle)); // If it comes here value is located on the cache. // found_row_cache_entry points to the value on cache, // and value_pinner has cleanup procedure for the cached entry. // After replayGetContextLog() returns, get_context.pinnable_slice_ // will point to cache entry buffer (or a copy based on that) and // cleanup routine under value_pinner will be delegated to // get_context.pinnable_slice_. Cache entry is released when // get_context.pinnable_slice_ is reset. value_pinner.RegisterCleanup(release_cache_entry_func, ioptions_.row_cache.get(), row_handle); replayGetContextLog(*found_row_cache_entry, user_key, get_context, &value_pinner); RecordTick(ioptions_.statistics, ROW_CACHE_HIT); found = true; } else { RecordTick(ioptions_.statistics, ROW_CACHE_MISS); } return found; }
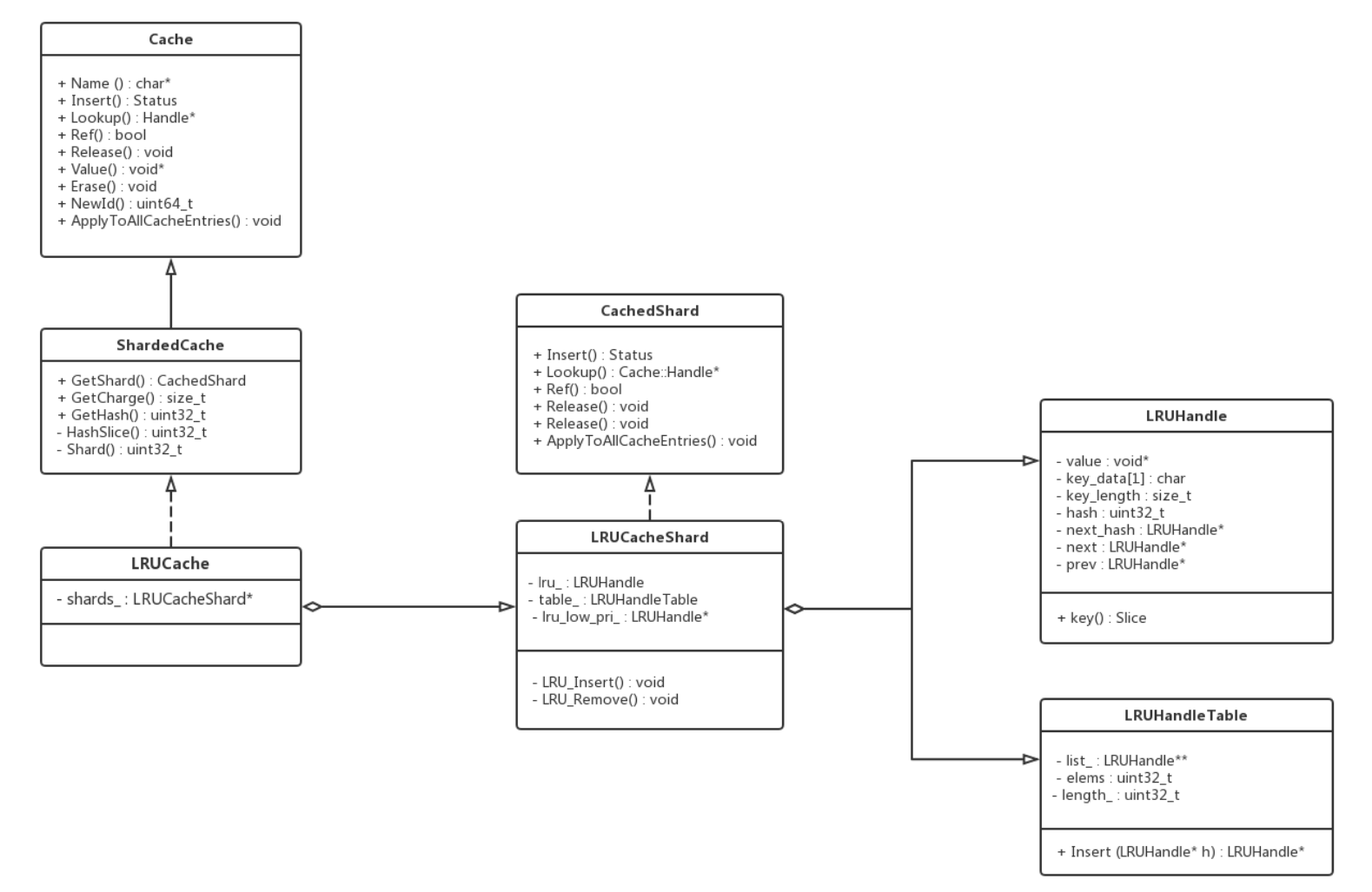
Cache::Handle* LRUCacheShard::Lookup(const Slice& key, uint32_t hash) { MutexLock l(&mutex_); LRUHandle* e = table_.Lookup(key, hash); if (e != nullptr) { assert(e->InCache()); if (!e->HasRefs()) { // The entry is in LRU since it's in hash and has no external references LRU_Remove(e); } e->Ref(); e->SetHit(); } return reinterpret_cast<Cache::Handle*>(e); }
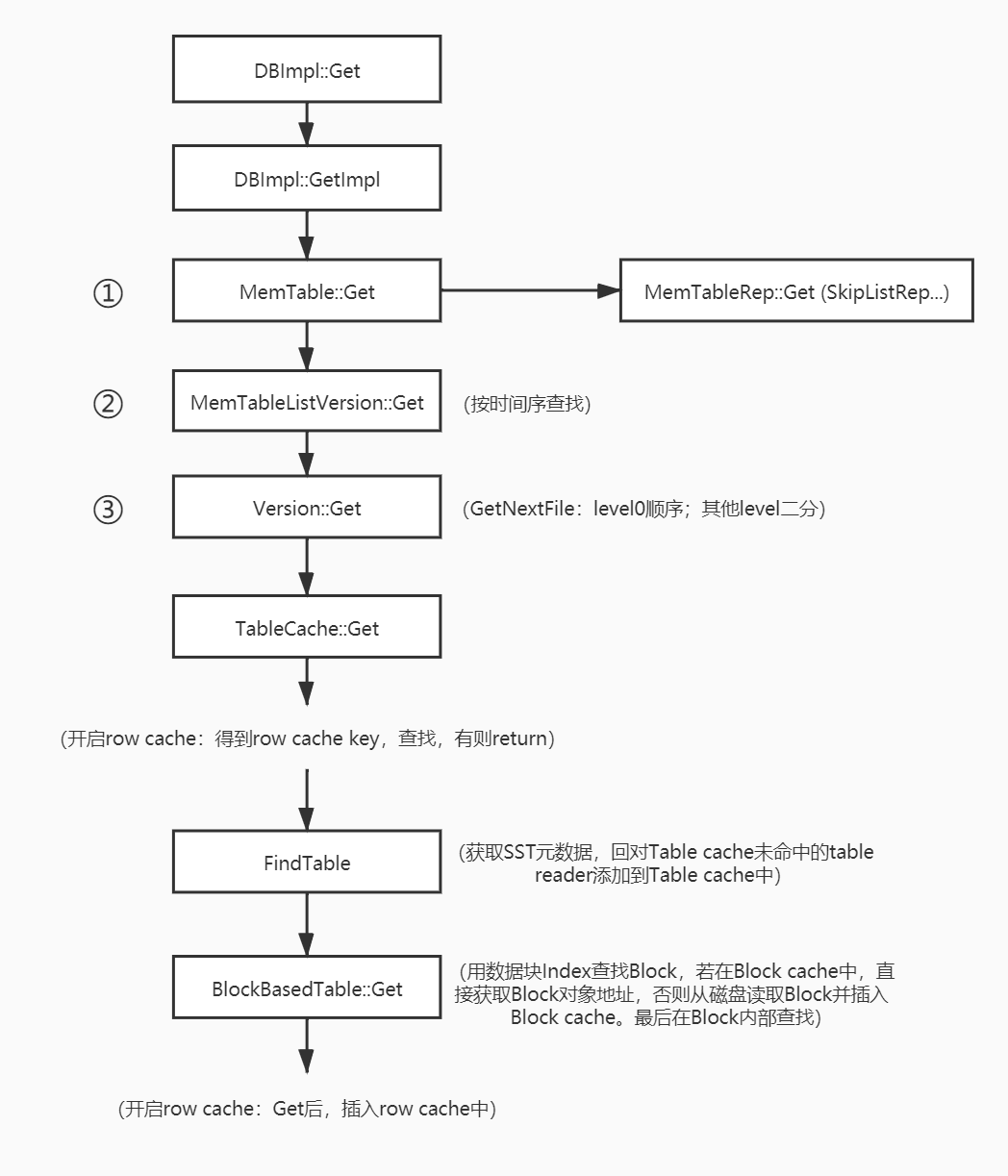
// Check row cache if enabled. Since row cache does not currently store // sequence numbers, we cannot use it if we need to fetch the sequence. if (ioptions_.row_cache && !get_context->NeedToReadSequence()) { auto user_key = ExtractUserKey(k); CreateRowCacheKeyPrefix(options, fd, k, get_context, row_cache_key); done = GetFromRowCache(user_key, row_cache_key, row_cache_key.Size(), get_context); if (!done) { row_cache_entry = &row_cache_entry_buffer; } } #endif // ROCKSDB_LITE Status s; TableReader* t = fd.table_reader; Cache::Handle* handle = nullptr; if (!done && s.ok()) { if (t == nullptr) { s = FindTable( file_options_, internal_comparator, fd, &handle, prefix_extractor, options.read_tier == kBlockCacheTier /* no_io */, true /* record_read_stats */, file_read_hist, skip_filters, level); if (s.ok()) { t = GetTableReaderFromHandle(handle); } } SequenceNumber* max_covering_tombstone_seq = get_context->max_covering_tombstone_seq(); if (s.ok() && max_covering_tombstone_seq != nullptr && !options.ignore_range_deletions) { std::unique_ptr<FragmentedRangeTombstoneIterator> range_del_iter( t->NewRangeTombstoneIterator(options)); if (range_del_iter != nullptr) { *max_covering_tombstone_seq = std::max( *max_covering_tombstone_seq, range_del_iter->MaxCoveringTombstoneSeqnum(ExtractUserKey(k))); } } if (s.ok()) { get_context->SetReplayLog(row_cache_entry); // nullptr if no cache. s = t->Get(options, k, get_context, prefix_extractor, skip_filters); get_context->SetReplayLog(nullptr); } else if (options.read_tier == kBlockCacheTier && s.IsIncomplete()) { // Couldn't find Table in cache but treat as kFound if no_io set get_context->MarkKeyMayExist(); s = Status::OK(); done = true; } }
#ifndef ROCKSDB_LITE // Put the replay log in row cache only if something was found. if (!done && s.ok() && row_cache_entry && !row_cache_entry->empty()) { size_t charge = row_cache_key.Size() + row_cache_entry->size() + sizeof(std::string); void* row_ptr = new std::string(std::move(*row_cache_entry)); ioptions_.row_cache->Insert(row_cache_key.GetUserKey(), row_ptr, charge, &DeleteEntry<std::string>); } #endif // ROCKSDB_LITE
if (handle != nullptr) { ReleaseHandle(handle); } return s; }
Status TableCache::FindTable(const FileOptions& file_options, const InternalKeyComparator& internal_comparator, const FileDescriptor& fd, Cache::Handle** handle, const SliceTransform* prefix_extractor, const bool no_io, bool record_read_stats, HistogramImpl* file_read_hist, bool skip_filters, int level, bool prefetch_index_and_filter_in_cache) { ... std::unique_ptr<TableReader> table_reader; s = GetTableReader(file_options, internal_comparator, fd, false /* sequential mode */, record_read_stats, file_read_hist, &table_reader, prefix_extractor, skip_filters, level, prefetch_index_and_filter_in_cache); if (!s.ok()) { assert(table_reader == nullptr); RecordTick(ioptions_.statistics, NO_FILE_ERRORS); // We do not cache error results so that if the error is transient, // or somebody repairs the file, we recover automatically. } else { s = cache_->Insert(key, table_reader.get(), 1, &DeleteEntry<TableReader>, handle); if (s.ok()) { // Release ownership of table reader. table_reader.release(); } ... return s; }