func (a *cloudHub) Start() { if !cache.WaitForCacheSync(beehiveContext.Done(), a.informersSyncedFuncs...) { klog.Errorf("unable to sync caches for objectSyncController") os.Exit(1) }
// start dispatch message from the cloud to edge node go a.messageq.DispatchMessage()
// check whether the certificates exist in the local directory, // and then check whether certificates exist in the secret, generate if they don't exist if err := httpserver.PrepareAllCerts(); err != nil { klog.Exit(err) } // TODO: Will improve in the future DoneTLSTunnelCerts <- true close(DoneTLSTunnelCerts)
// HttpServer mainly used to issue certificates for the edge go httpserver.StartHTTPServer()
servers.StartCloudHub(a.messageq)
if hubconfig.Config.UnixSocket.Enable { // The uds server is only used to communicate with csi driver from kubeedge on cloud. // It is not used to communicate between cloud and edge. go udsserver.StartServer(hubconfig.Config.UnixSocket.Address) } }
func (q *ChannelMessageQueue) DispatchMessage() { for { select { case <-beehiveContext.Done(): klog.Warning("Cloudhub channel eventqueue dispatch message loop stopped") return default: } msg, err := beehiveContext.Receive(model.SrcCloudHub) klog.V(4).Infof("[cloudhub] dispatchMessage to edge: %+v", msg) if err != nil { klog.Info("receive not Message format message") continue } nodeID, err := GetNodeID(&msg) if nodeID == "" || err != nil { klog.Warning("node id is not found in the message") continue } if isListResource(&msg) { q.addListMessageToQueue(nodeID, &msg) } else { q.addMessageToQueue(nodeID, &msg) } } }
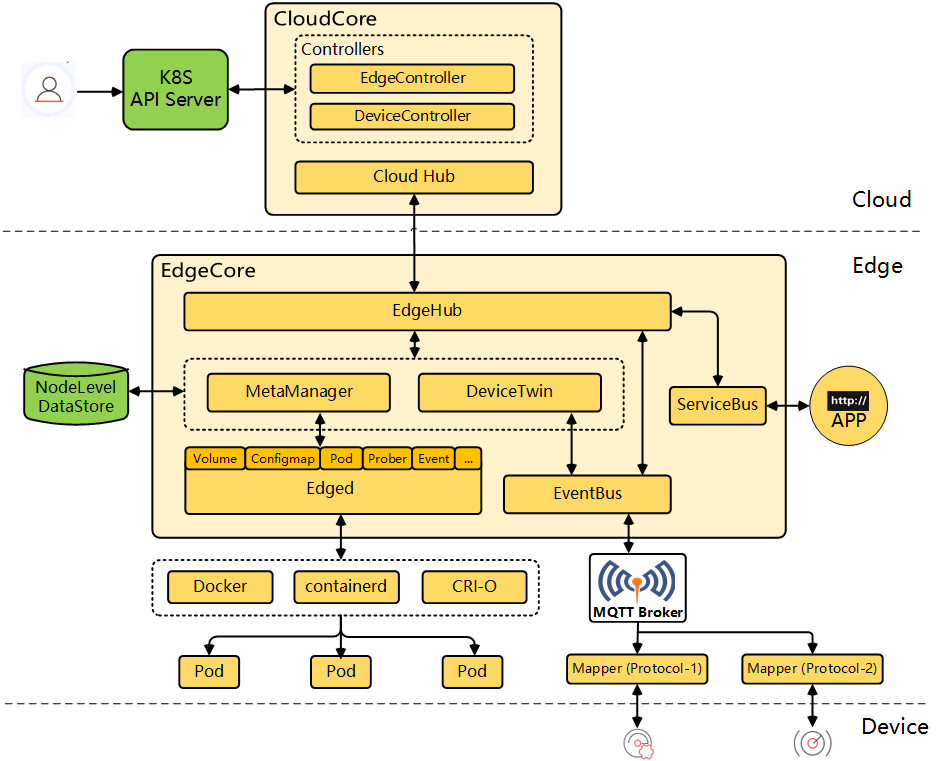
StartCloudHub
StartCloudHub 的代码如下:
1 2 3 4 5 6 7 8 9 10 11
func StartCloudHub(messageq *channelq.ChannelMessageQueue) { handler.InitHandler(messageq) // start websocket server if hubconfig.Config.WebSocket.Enable { go startWebsocketServer() } // start quic server if hubconfig.Config.Quic.Enable { go startQuicServer() } }
// registerModules register all the modules started in edgecore func registerModules(c *v1alpha1.EdgeCoreConfig) { devicetwin.Register(c.Modules.DeviceTwin, c.Modules.Edged.HostnameOverride) edged.Register(c.Modules.Edged) edgehub.Register(c.Modules.EdgeHub, c.Modules.Edged.HostnameOverride) eventbus.Register(c.Modules.EventBus, c.Modules.Edged.HostnameOverride) metamanager.Register(c.Modules.MetaManager) servicebus.Register(c.Modules.ServiceBus) edgestream.Register(c.Modules.EdgeStream, c.Modules.Edged.HostnameOverride, c.Modules.Edged.NodeIP) test.Register(c.Modules.DBTest) // Note: Need to put it to the end, and wait for all models to register before executing dbm.InitDBConfig(c.DataBase.DriverName, c.DataBase.AliasName, c.DataBase.DataSource) }