缓存设计
概述
在设计与开发高性能的系统时,基本都离不开缓存的设计。没有缓存对系统的加速和阻挡大量的请求直接落到系统的底层,系统是很难撑住高并发的冲击。无论是在 CPU 的 L1,L2,L3 缓存,数据库的 sql 语句执行缓存,系统应用的本地缓存,缓存总是解决性能的一把利器。本文主要探讨缓存带来的问题以及缓存方案的设计。
缓存带来的问题
缓存一致性
引入缓存后,主要是解决读的性能问题,但是数据总是要更新的,会存在操作隔离性和更新原子性的问题,是先更新缓存还是先更新数据库呢?
操作隔离性:一条数据的更新涉及到存储和缓存两套系统,如果多个线程同时操作一条数据,并且没有方案保证多个操作之间的有序执行,就可能会发生更新顺序错乱导致数据不一致的问题
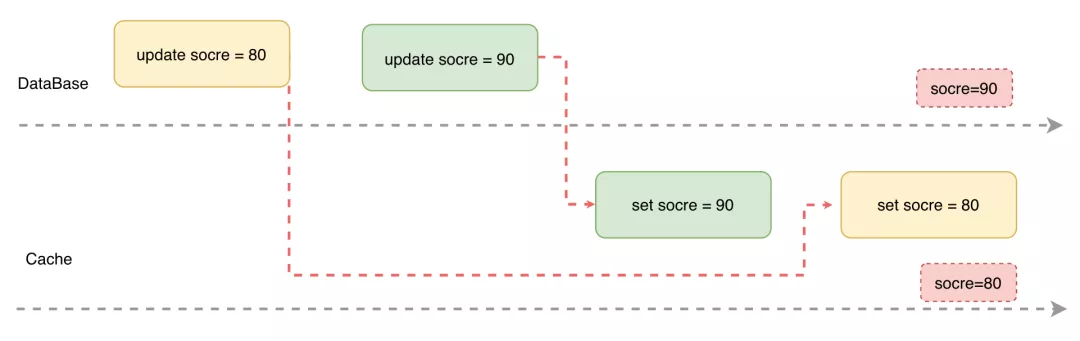
更新原子性:引入缓存后,我们需要保证缓存和存储要么同时更新成功,要么同时更新失败,否则部分更新成功就会导致缓存和存储数据不一致的问题
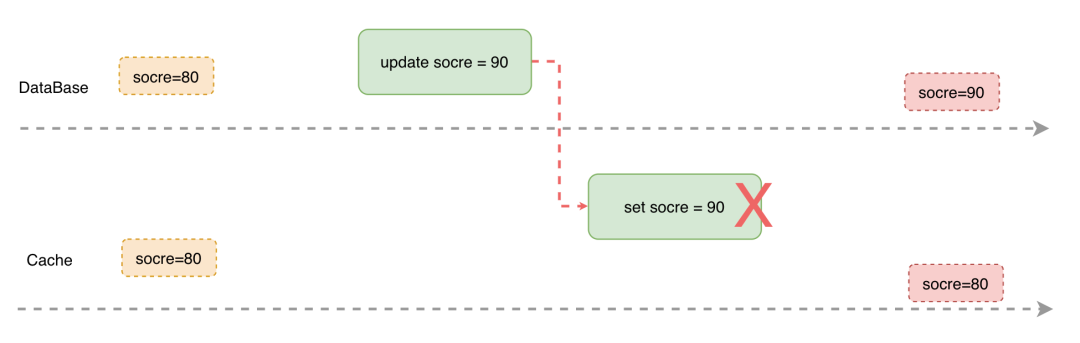
- 先更新缓存再更新数据库:更新缓存后,后续的读操作都会先从缓存获取从而获取的是最新的数据,但是如果第二步更新数据库失败,那么数据需要回滚,导致先前获取的数据是脏数据来带不可逆的业务影响
- 先更新数据库后更新缓存:先更新数据库,但是缓存没有更新,再将数据从数据库同步到缓存这一过程中,所有的读操作读的都是旧数据,会带来一定问题,牺牲小概率的一致性
缓存击穿
缓存击穿是指:业务操作访问缓存时,没有访问到数据,又去访问数据库,但是从数据库也没有查询到数据,也不写入缓存,从而导致这些操作每次都需要访问数据库,造成缓存击穿。
解决办法一般有两种:
- 将每次从数据库获取的数据,即使是空值也先写入缓存,但是过期时间设置得比较短,后续的访问都直接从缓存中获取空值返回即可
- 通过 Bloom filter 记录 key 是否存在,从而避免无效数据的查询
缓存雪崩
缓存雪崩是指:由于大量的热数据设置了相同或接近的过期时间,导致缓存在某一时刻密集失效,大量请求全部转发到数据库,或者是某个冷数据瞬间涌入大量访问数据库。
主要解决方法:
- 所有数据的过期时间不要设置成一样,防止出现数据批量失效,导致缓存雪崩的情况
- 采用互斥锁的方式:这里需要使用到分布式锁,在缓存失效后,如果访问同一数据的操作需要访问数据并去更新缓存时,对这些操作都加锁,保证只有一个线程去访问数据并更新缓存,后续所有操作还是从缓存中获取数据,如果一定时间没有获取到就返回默认值或返回空值。这样可以防止数据库压力增大,但是用户体验会降低
- 后台更新:业务操作需要访问缓存没有获取到数据时,不访问数据库更新缓存,只返回默认值。通过后台线程去更新缓存,这里有两种更新方式:
- 启动定时任务定时扫描所有缓存,如果不存在就更新,该方法导致扫描 key 间隔时间过长,数据更新不实时,期间业务操作一直会返回默认值,用户体验比较差
- 业务线程发现缓存失效后通过消息队列去更新缓存,这里因为是分布式的所以可能有很多条消息,需要考虑消息的幂等性。这种方式依赖消息队列,但是缓存更新及时,用户体验比较好,缺点是系统复杂度增高了
缓存方案的设计
读取
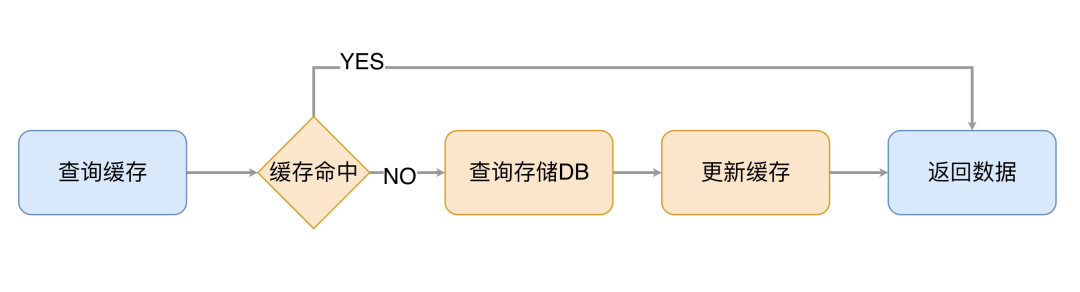
读数据流程很简单,先去缓存读取数据,如果缓存 MISS,则需要从存储中读取数据,并将数据更新到缓存系统中,整个流程如下所示:
更新
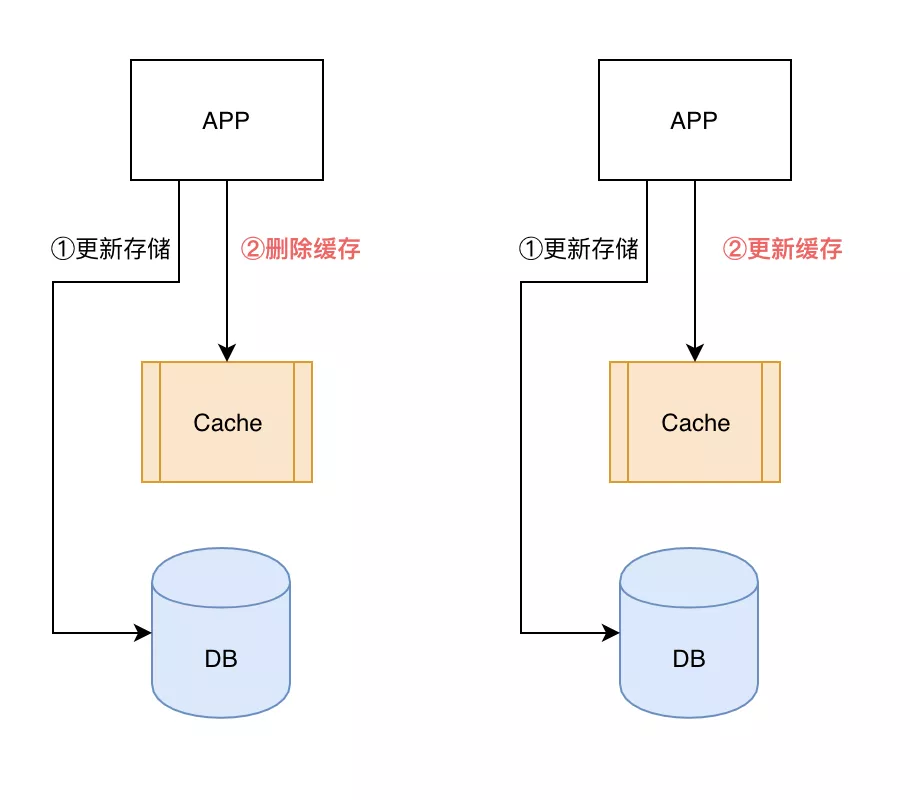
通常选择以下方案,保障数据可靠性,尽量减少数据不一致的出现,通过 TTL 超时机制在一定时间段后自动解决数据不一致现象:
- 更新数据库,保证数据可靠性
- 更新缓存,有以下 2 个策略:
- 惰性更新:删除缓存中对应的 item,等待下次读 MISS 再缓存(推荐)
- 积极更新:将最新的数据更新到缓存
淘汰
缓存的作用是将热点数据缓存到内存实现加速,内存的成本要远高于磁盘,因此我们通常仅仅缓存热数据在内存,冷数据需要定期的从内存淘汰,数据的淘汰通常有两种方案:
- 主动淘汰。通过对 Key 设置 TTL 的方式来让 Key 定期淘汰,以保障冷数据不会长久的占有内存(推荐)
- 被动淘汰。当缓存已用内存超过 Maxmemory 限定时触发淘汰,在 Maxmemory 的场景下缓存的质量是不可控的,因为每次缓存一个 Key 都可能需要去淘汰一个 Key