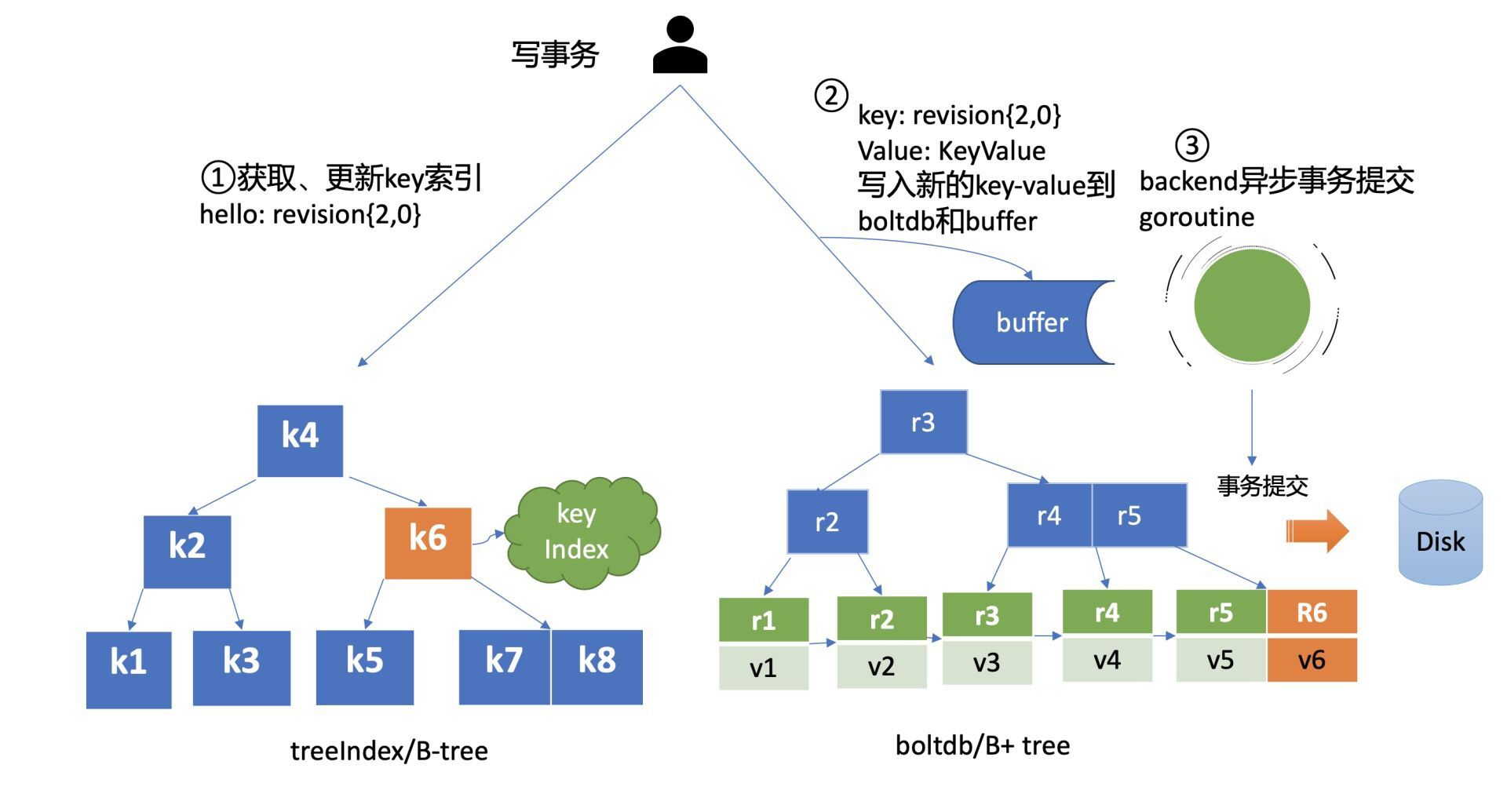
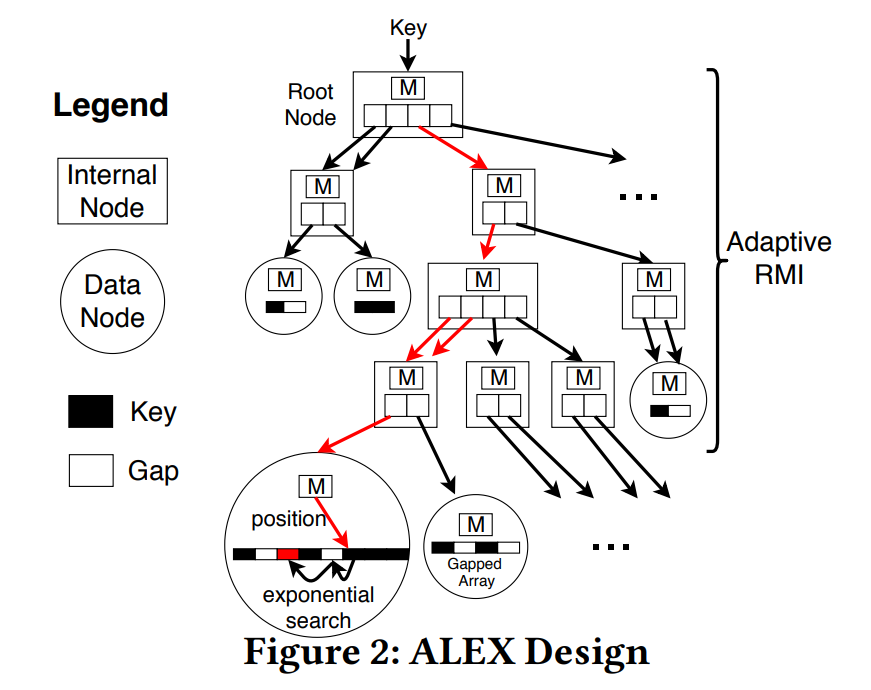
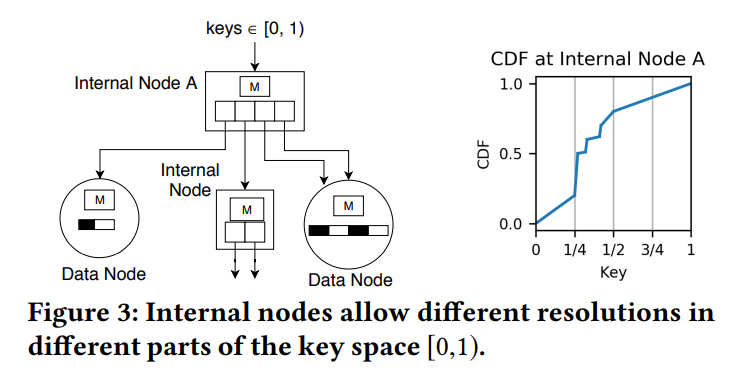
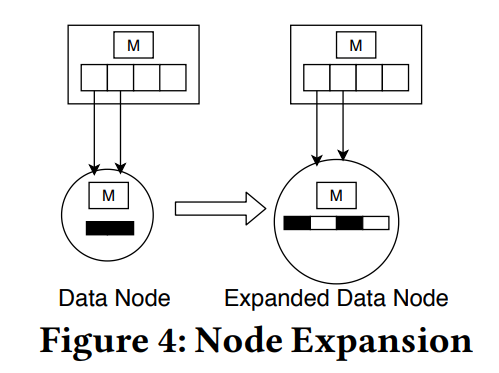
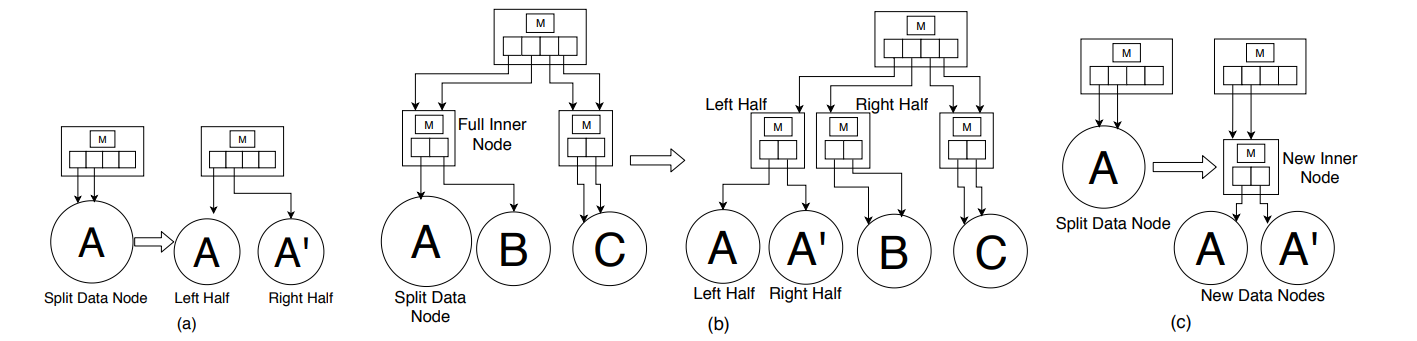
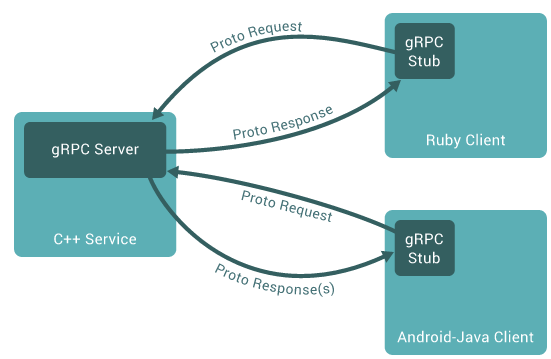
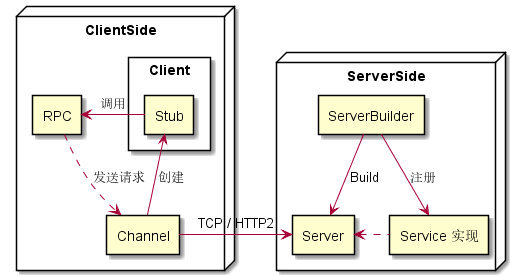
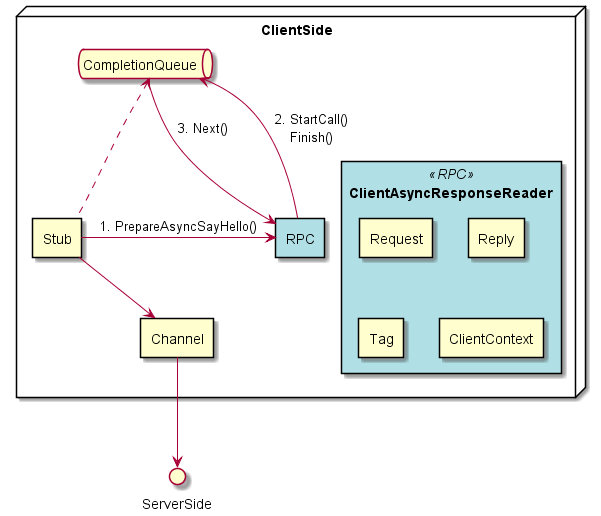
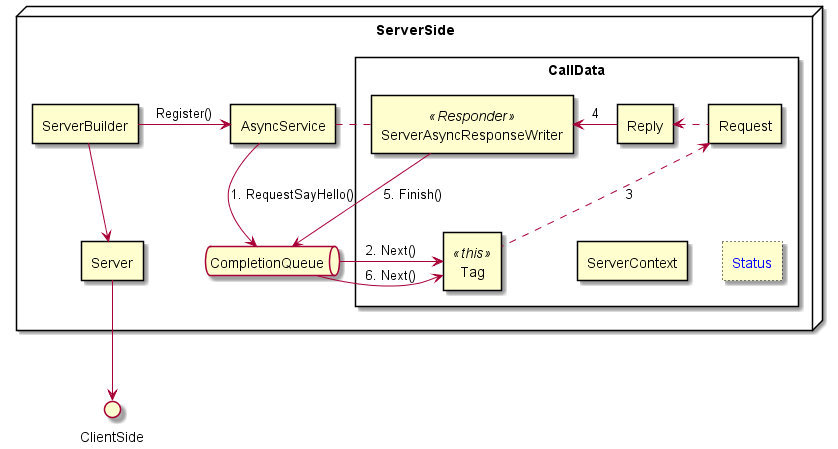
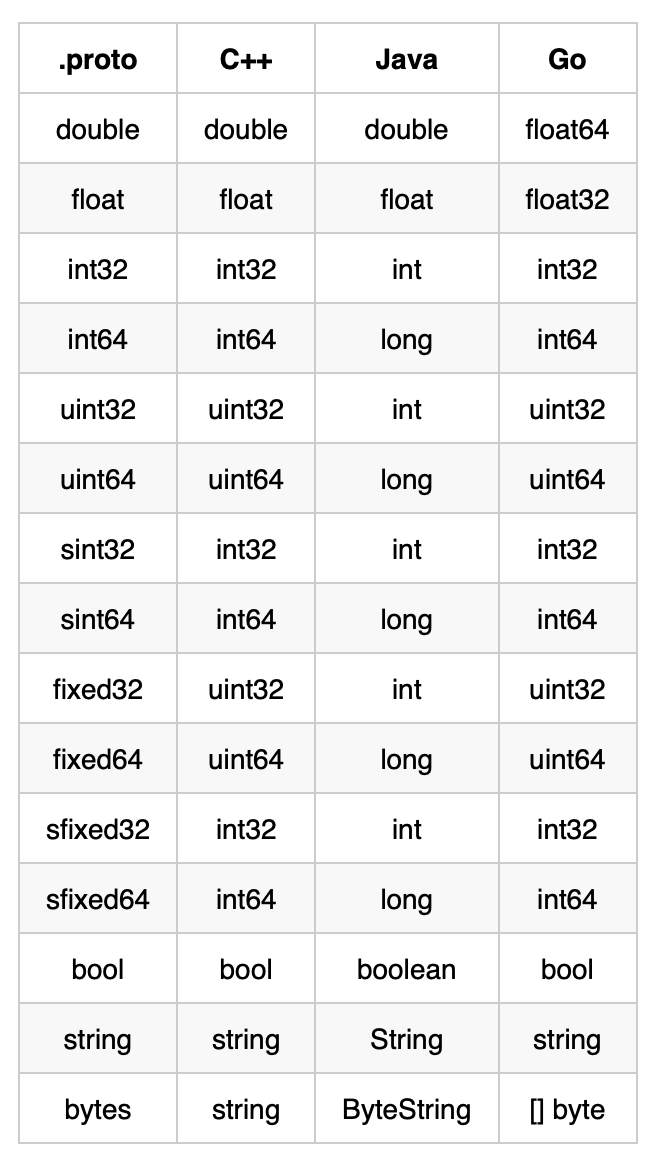
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
| func (uc *UpstreamController) updateNodeStatus() {
for {
select {
case <-beehiveContext.Done():
klog.Warning("stop updateNodeStatus")
return
case msg := <-uc.nodeStatusChan:
klog.V(5).Infof("message: %s, operation is: %s, and resource is %s", msg.GetID(), msg.GetOperation(), msg.GetResource())
data, err := msg.GetContentData()
if err != nil {
klog.Warningf("message: %s process failure, get content data failed with error: %s", msg.GetID(), err)
continue
}
namespace, err := messagelayer.GetNamespace(msg)
if err != nil {
klog.Warningf("message: %s process failure, get namespace failed with error: %s", msg.GetID(), err)
continue
}
name, err := messagelayer.GetResourceName(msg)
if err != nil {
klog.Warningf("message: %s process failure, get resource name failed with error: %s", msg.GetID(), err)
continue
}
switch msg.GetOperation() {
case model.InsertOperation:
_, err := uc.kubeClient.CoreV1().Nodes().Get(context.Background(), name, metaV1.GetOptions{})
if err == nil {
klog.Infof("node: %s already exists, do nothing", name)
uc.nodeMsgResponse(name, namespace, common.MessageSuccessfulContent, msg)
continue
}
if !errors.IsNotFound(err) {
errLog := fmt.Sprintf("get node %s info error: %v , register node failed", name, err)
klog.Error(errLog)
uc.nodeMsgResponse(name, namespace, errLog, msg)
continue
}
node := &v1.Node{}
err = json.Unmarshal(data, node)
if err != nil {
errLog := fmt.Sprintf("message: %s process failure, unmarshal marshaled message content with error: %s", msg.GetID(), err)
klog.Error(errLog)
uc.nodeMsgResponse(name, namespace, errLog, msg)
continue
}
if _, err = uc.createNode(name, node); err != nil {
errLog := fmt.Sprintf("create node %s error: %v , register node failed", name, err)
klog.Error(errLog)
uc.nodeMsgResponse(name, namespace, errLog, msg)
continue
}
uc.nodeMsgResponse(name, namespace, common.MessageSuccessfulContent, msg)
case model.UpdateOperation:
nodeStatusRequest := &edgeapi.NodeStatusRequest{}
err := json.Unmarshal(data, nodeStatusRequest)
if err != nil {
klog.Warningf("message: %s process failure, unmarshal marshaled message content with error: %s", msg.GetID(), err)
continue
}
getNode, err := uc.kubeClient.CoreV1().Nodes().Get(context.Background(), name, metaV1.GetOptions{})
if errors.IsNotFound(err) {
klog.Warningf("message: %s process failure, node %s not found", msg.GetID(), name)
continue
}
if err != nil {
klog.Warningf("message: %s process failure with error: %s, namespaces: %s name: %s", msg.GetID(), err, namespace, name)
continue
}
// TODO: comment below for test failure. Needs to decide whether to keep post troubleshoot
// In case the status stored at metadata service is outdated, update the heartbeat automatically
for i := range nodeStatusRequest.Status.Conditions {
if time.Since(nodeStatusRequest.Status.Conditions[i].LastHeartbeatTime.Time) > time.Duration(uc.config.NodeUpdateFrequency)*time.Second {
nodeStatusRequest.Status.Conditions[i].LastHeartbeatTime = metaV1.NewTime(time.Now())
}
}
if getNode.Annotations == nil {
getNode.Annotations = make(map[string]string)
}
for name, v := range nodeStatusRequest.ExtendResources {
if name == constants.NvidiaGPUScalarResourceName {
var gpuStatus []types.NvidiaGPUStatus
for _, er := range v {
gpuStatus = append(gpuStatus, types.NvidiaGPUStatus{ID: er.Name, Healthy: true})
}
if len(gpuStatus) > 0 {
data, _ := json.Marshal(gpuStatus)
getNode.Annotations[constants.NvidiaGPUStatusAnnotationKey] = string(data)
}
}
data, err := json.Marshal(v)
if err != nil {
klog.Warningf("message: %s process failure, extend resource list marshal with error: %s", msg.GetID(), err)
continue
}
getNode.Annotations[string(name)] = string(data)
}
// Keep the same "VolumesAttached" attribute with upstream,
// since this value is maintained by kube-controller-manager.
nodeStatusRequest.Status.VolumesAttached = getNode.Status.VolumesAttached
if getNode.Status.DaemonEndpoints.KubeletEndpoint.Port != 0 {
nodeStatusRequest.Status.DaemonEndpoints.KubeletEndpoint.Port = getNode.Status.DaemonEndpoints.KubeletEndpoint.Port
}
getNode.Status = nodeStatusRequest.Status
node, err := uc.kubeClient.CoreV1().Nodes().UpdateStatus(context.Background(), getNode, metaV1.UpdateOptions{})
if err != nil {
klog.Warningf("message: %s process failure, update node failed with error: %s, namespace: %s, name: %s", msg.GetID(), err, getNode.Namespace, getNode.Name)
continue
}
nodeID, err := messagelayer.GetNodeID(msg)
if err != nil {
klog.Warningf("Message: %s process failure, get node id failed with error: %s", msg.GetID(), err)
continue
}
resource, err := messagelayer.BuildResource(nodeID, namespace, model.ResourceTypeNode, name)
if err != nil {
klog.Warningf("Message: %s process failure, build message resource failed with error: %s", msg.GetID(), err)
continue
}
resMsg := model.NewMessage(msg.GetID()).
SetResourceVersion(node.ResourceVersion).
FillBody(common.MessageSuccessfulContent).
BuildRouter(modules.EdgeControllerModuleName, constants.GroupResource, resource, model.ResponseOperation)
if err = uc.messageLayer.Response(*resMsg); err != nil {
klog.Warningf("Message: %s process failure, response failed with error: %s", msg.GetID(), err)
continue
}
klog.V(4).Infof("message: %s, update node status successfully, namespace: %s, name: %s", msg.GetID(), getNode.Namespace, getNode.Name)
default:
klog.Warningf("message: %s process failure, node status operation: %s unsupported", msg.GetID(), msg.GetOperation())
continue
}
klog.V(4).Infof("message: %s process successfully", msg.GetID())
}
}
}
|