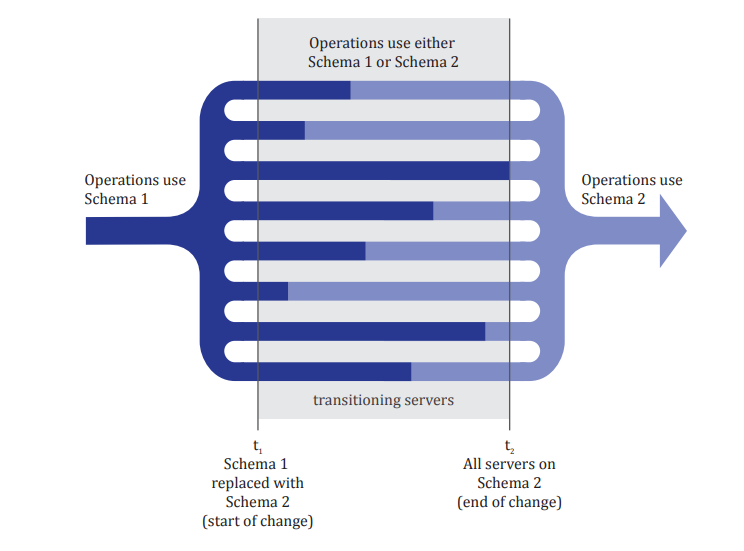
Optimization of Common Table Expressions in MPP Database Systems 概述
背景
论文基于 Orca 对非递归的 CTE 进行了形式化表达和优化,贡献总结如下:
- 在查询中使用 CTE 的上下文中优化 CTE
- 对于查询中的每个 CTE 引用,CTE 不会每次重新优化,仅在需要的时候才进行,例如下推 fitlers 或者 sort 操作
- 基于 cost 来决定是否对 CTE 进行内联
- 减少 plan 的搜索空间,加速查询执行,包括下推 predicates 到 CTE,如果 CTE 被引用一次则始终内联,消除掉没有被引用的 CTE
- 避免死锁,保证 CTE producer 在 CTE consumer 之前执行
REPRESENTATION OF CTEs
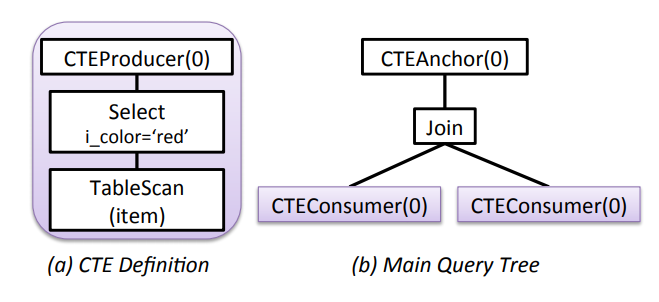
- CTEProducer:一个 CTE 定义对应一个 CTEProducer
- CTEConsumer:query 中引用 CTE 的地方
- CTEAnchor:query 中定义 CTE 的 node,CTE 只能被该 CTEAnchor 的子树中引用
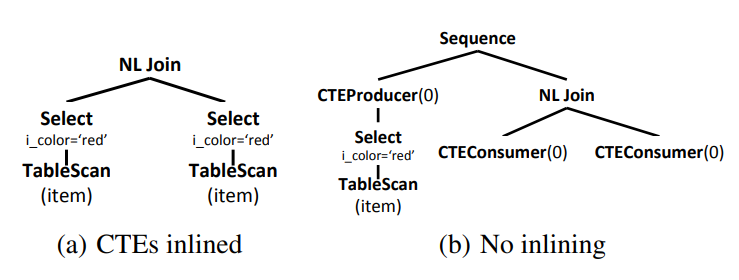
- Sequence:按序执行它的孩子节点,先执行左节点,再执行右节点,并把右节点做为返回值
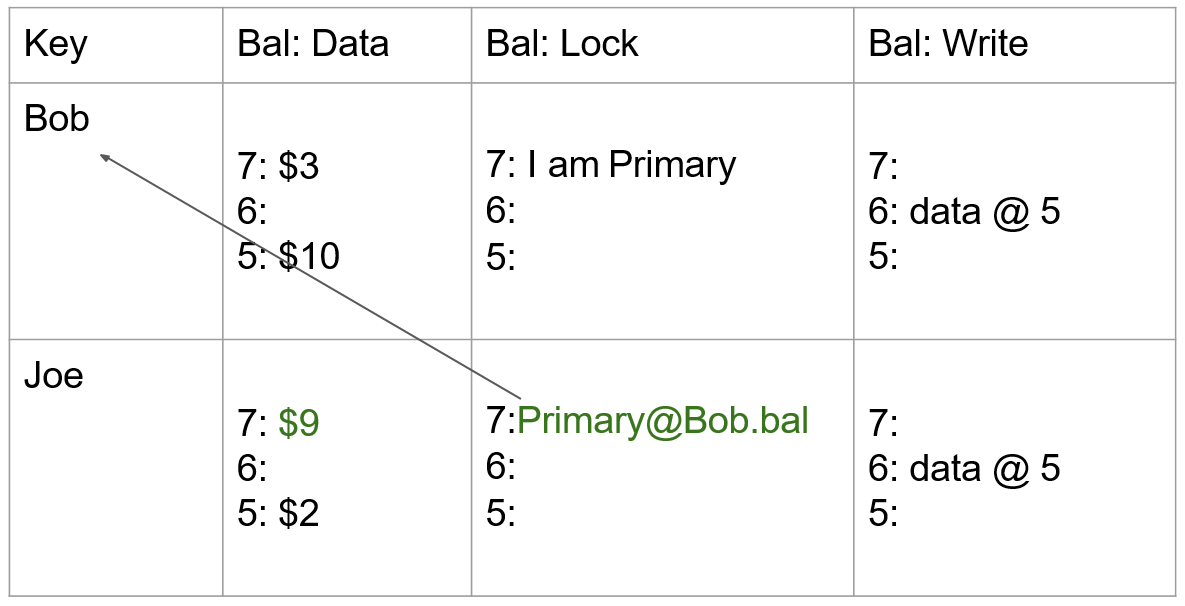
对于此查询:
1 | WITH v AS (SELECT i_brand FROM item WHERE i_color = ’red’) |
它的 Logical representation 如下所示:
它的 Execution plans 如下所示:
PLAN ENUMERATION
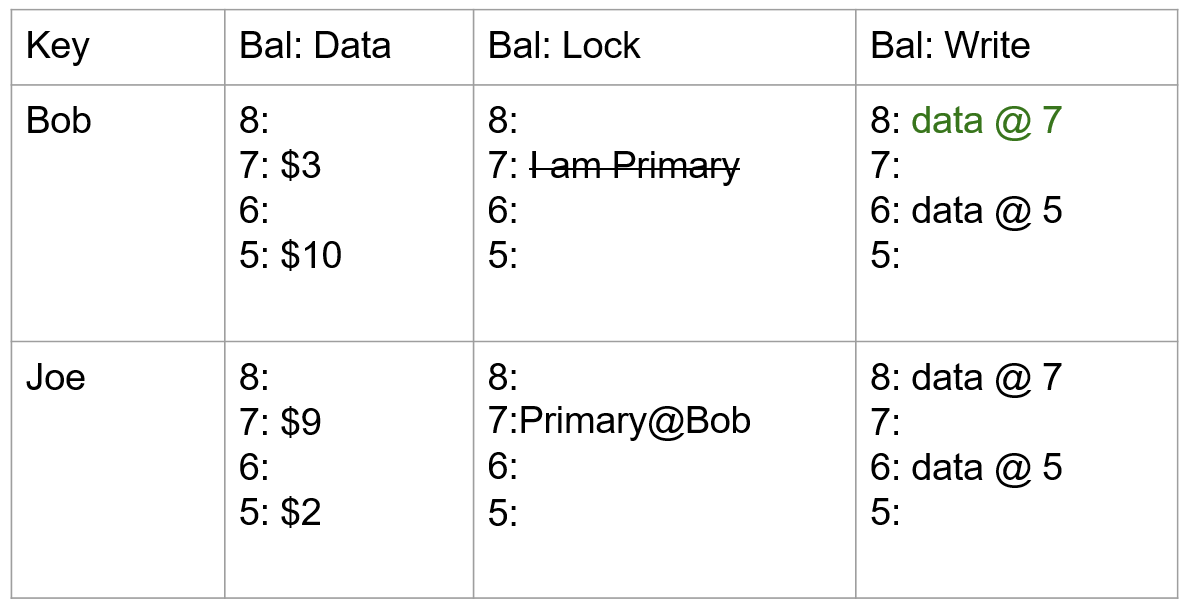
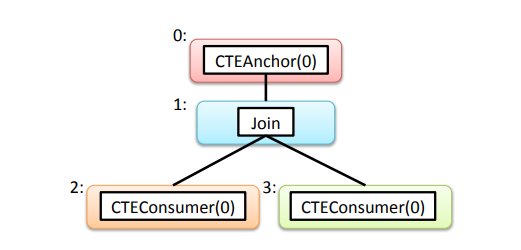
CTE 是否内联需要取决于 cost,因此需要枚举出 CTE 在不同引用地方内联前后的计划代价。Orca 中定义了 Memo,下图是初始的逻辑查询在 Memo 中的结构,每个编号就是一个 Memo Group:
Transformation Rules
Transformation Rules 可以看做 Memo Group 一个输入(或者一个函数),Memo Group 根据这个规则展开产生另一些 expression 放在同一个 Memo Group 中。对于每个 CTE,我们生成内联或不内联 CTE 的备选方案。
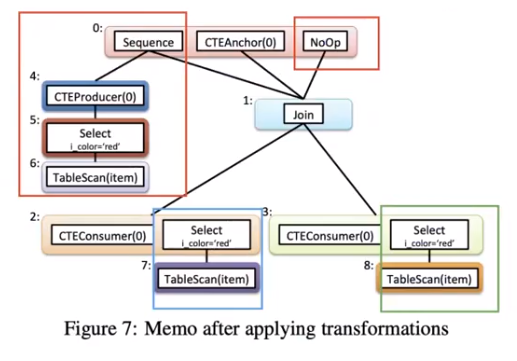
第一条规则应用于 CTEAnchor 运算符。它在 Group 0 中生成一个 Sequence 操作符,这样序列的左节点就是表示 CTE 定义的整个 Plan Tree —— 根据需要创建尽可能多的新 Group (Group 4、5和6) —— 序列的右节点就是 CTEAnchor (Group 1) 的原始节点。
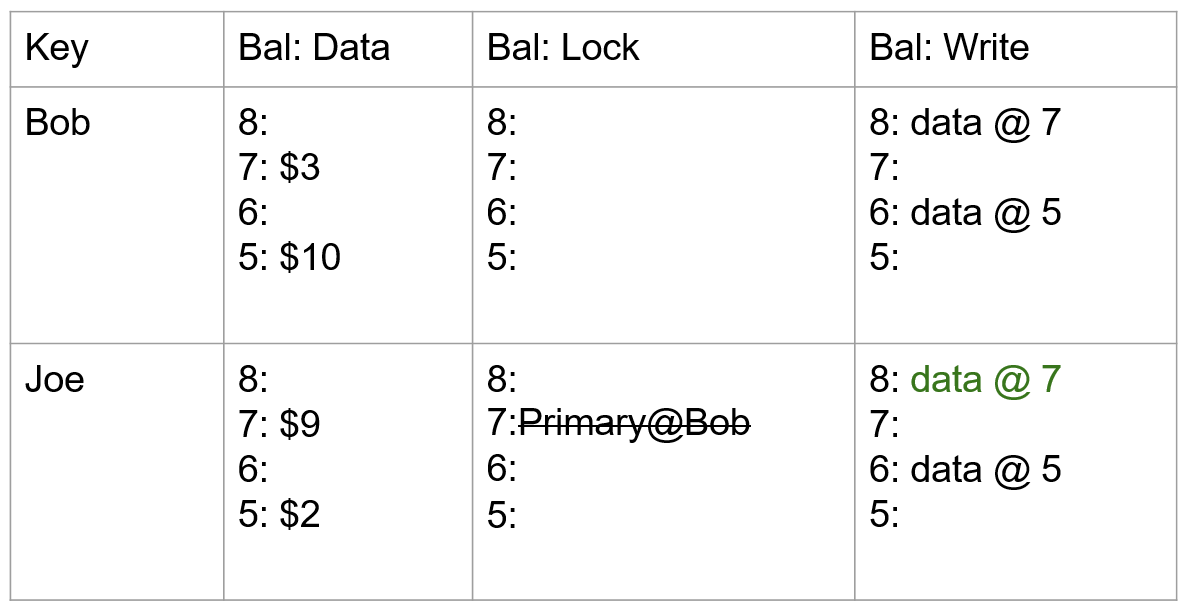
第二条规则也应用于 CTEAnchor,生成 Group 0 中的 NoOp 运算符,其孩子节点是 CTEAnchor 的孩子节点(Group 1)。
第三条规则应用于 CTEConsumer 运算符,生成 CTE 定义的副本,该副本与 CTEConsumer 属于同一 Group。例如,Group 2 中的 CTEConsumer,添加了 CTE 定义 Select 操作符,并将其子操作符 TableScan 添加到新Group(Group 7)。
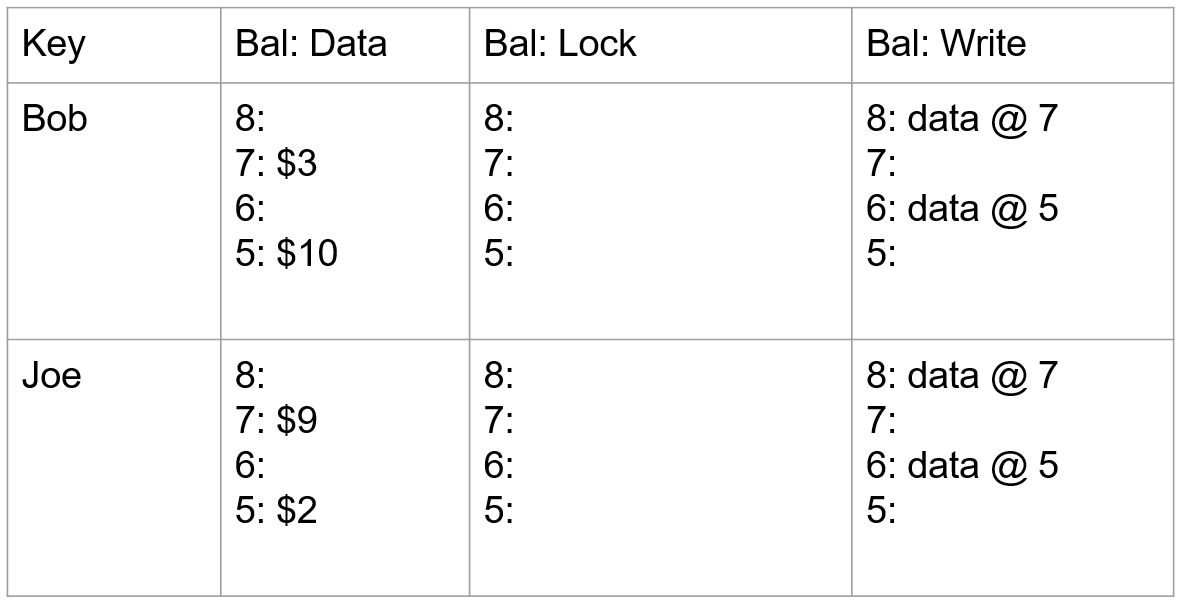
该方法产生的 Plan Tree 的组合中并不都是有效的,比如:
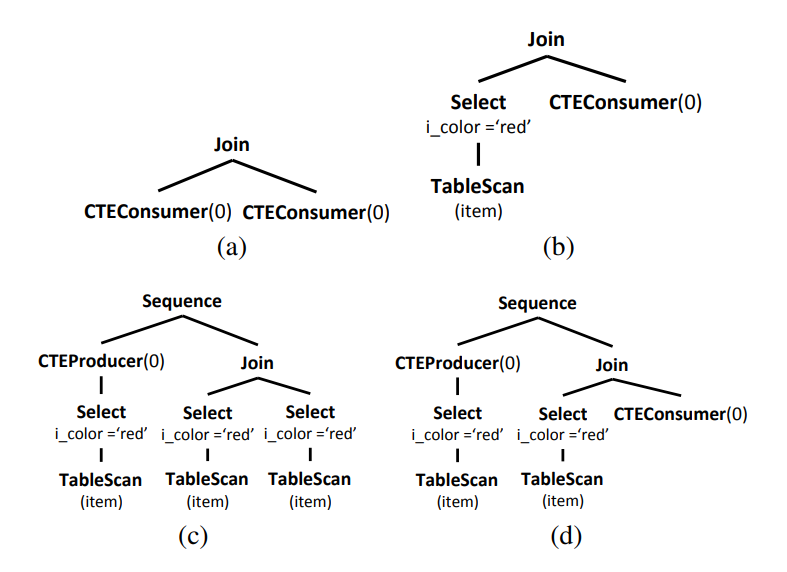
a 和 b 都没有 CTEProducer;c 有一个 CTEProducer,没有 CTEConsumer;d 中的 Plan 是有效的,但是只有一个 CTEConsumer 对应于包含的 CTEProducer,是一个失败的 Plan。
通过 Memo 的机制来表达不同的 Plan,基于 cost 选择是否内联。在一个 query 中,CTE 可能有的内联,而有的不内联。内联的好处是能进行普通 query 的优化,比如:下推 predicates,distribution,sorting 等。例如:
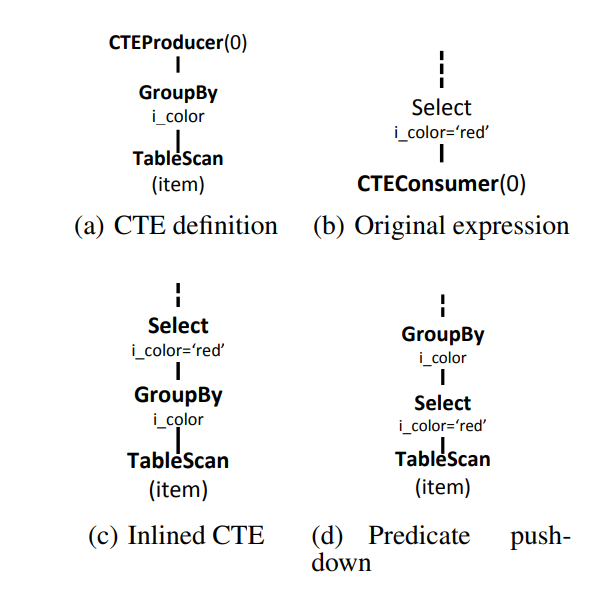
CTEConsumer 上游有 predicate: i_color=’red’,Orca在默认情况下会将谓词下推,使其从表达式 c 变为表达式 d。
Avoiding Invalid Plans
上述产生的 Plan Tree 会很多,所以需要裁剪掉一些无效的 Plan,例如,使用了 CTEConsumer 却没有 CTEProducer。裁剪算法如下:

CTESpec 表示一个 CTE 的属性对(id, type),比如:(1, ‘c’),cteid = 1,type 是 CTEConsumer。该算法简单来说就是遍历 Tree,检查 CTEConsumer 和 CTEProduct 是否配对。具体描述如下:
- 先计算自身的 CTESpec;
- 遍历所有子节点:
- 计算对于该子节点的 CTESpec 的 Request,输入是:前面兄弟节点以及父节点的 specList,来自父节点的 reqParent,得到该子节点应该满足的 reqChild;
- 子节点调用该函数 DeriveCTEs(child, reqChild),递归返回子节点的有效的 CTESpecs,即 specChild;
- 把子节点 DeriveCTE 返回的 specChild 追加到 specList。如果发现有一对 CTEProducer 和 CTEConsumer就从 specList 中去除掉。
- 对比遍历所有子节点后得到的 specList 与传入的 reqParent 是否 match。如果匹配,则返回当前的 specList。
Optimizations Across Consumers
上述算法可以枚举出所有 CTE 是否内联的 Plan,另外还有一些其他优化 CTE 的方法。
Predicate Push-down
1 | WITH v as (SELECT i_brand, i_color FROM item |
把一个 CTEProducer 对应所有的 CTEConsumer 的 predicates,下推到该 CTEProducer 上,条件通过 OR 组合起来,减少物化的数据量。(注意:因为下推到 CTEProducer 的 predicate 是通过 OR 连接的,因此 CTEConsumer 仍然需要执行原来的 predicate。)
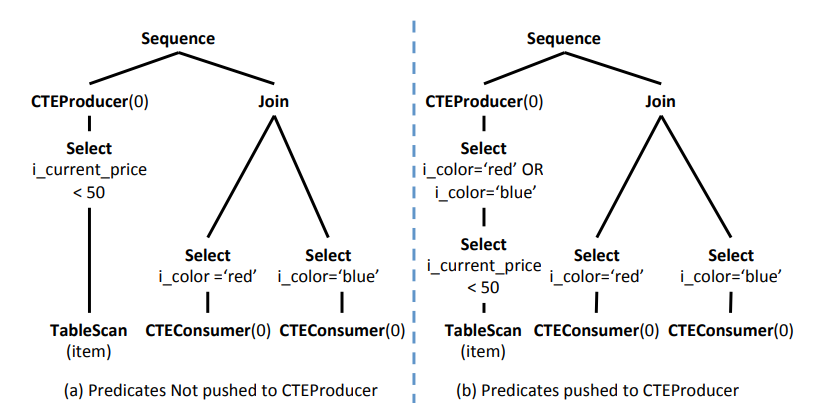
Always Inlining Single-use CTEs
1 | WITH v as (SELECT i_color FROM item |
如果只有一个 CTEConsumer,则始终内联 CTE。
Elimination of unused CTEs
1 | WITH v as (SELECT i_color FROM item |
CTE v 在上述 query 中没有被使用,这种情况可以消除 CTE。另外,对于如下 query:
1 | WITH v as (SELECT i_current_price p FROM item |
CTE v 被引用了两次,而 CTE w 从未被引用。因此,我们可以消除 w 的定义。并且,这样做去掉了对 v 的唯一引用,这意味着我们还可以消除 v 的定义。
CONTEXTUALIZED OPTIMIZATION
对 CTE 是否内联进行枚举之后,Plan 中不同的 CTEConsumer 可能使用不同的优化方案(内联或不内联、下推等)。
Enforcing Physical Properties
Orca 通过 top-down 发送处理 Memo Group 中的优化请求来优化候选计划。优化请求是一组表达式要满足的 Physical Properties 上的要求,包括 sort order, distribution, rewindability, CTEs 和 data partitioning 等,也可以没有(即 ANY)。下图以 distribution 为例子,CTE 需要在不同的上下文中满足不同的 Physical Properties。
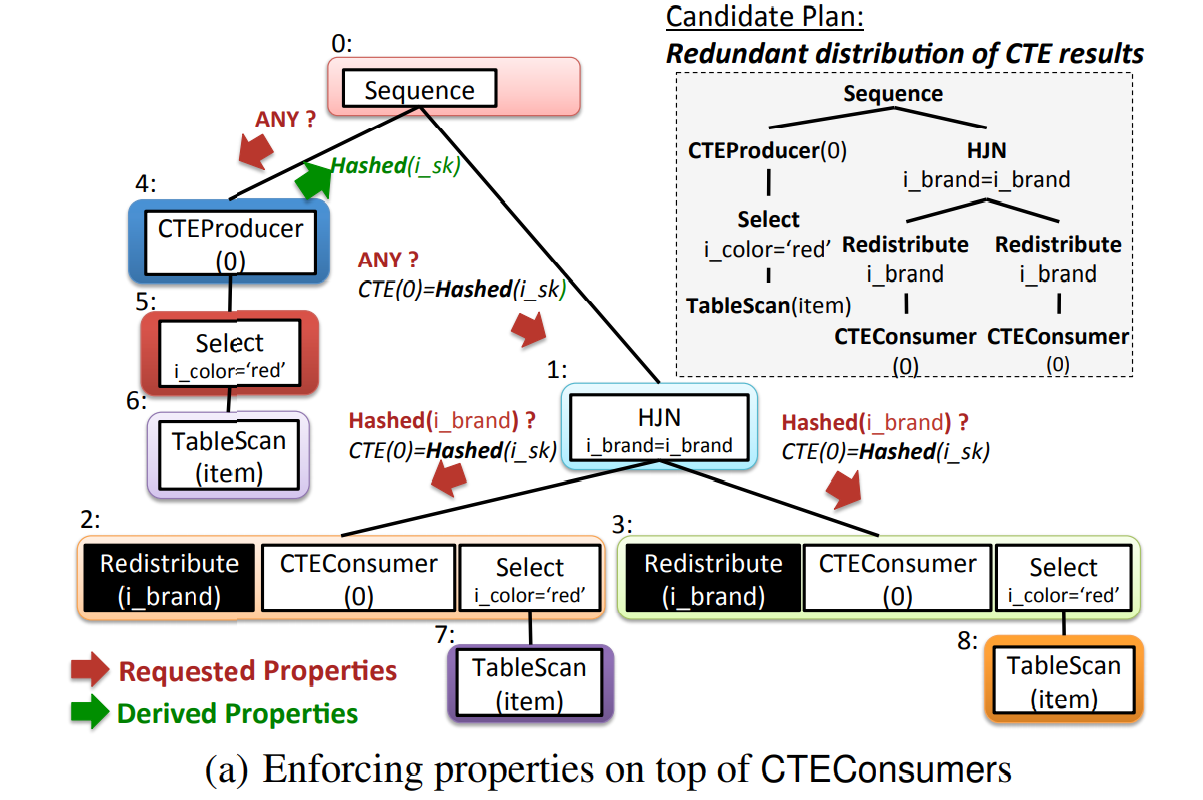
- Sequence 算子对 CTEProducer 发射 ANY 的 prop 请求,返回 Hashed(i_sk) 的 prop(表 item 按 i_sk 这一列进行哈希分布);
- 上述的 prop 发送到右子树中(结合自身 prop 和父节点的 prop),右子树中的 HashJoin 节点的连接条件需要子节点的数据基于 i_brand 哈希分布,发送请求到 group 2 和 group 3 的 CTEConsumer 中,而 CTEConsumer 并不满足 i_brand 哈希分布的要求,而父节点又需要此 prop,这时就需要在两个 CTEConsumer 分别添加 Redistribute 的算子,把数据按 i_brand 进行哈希,这样才能满足 HashJoin 的要求。
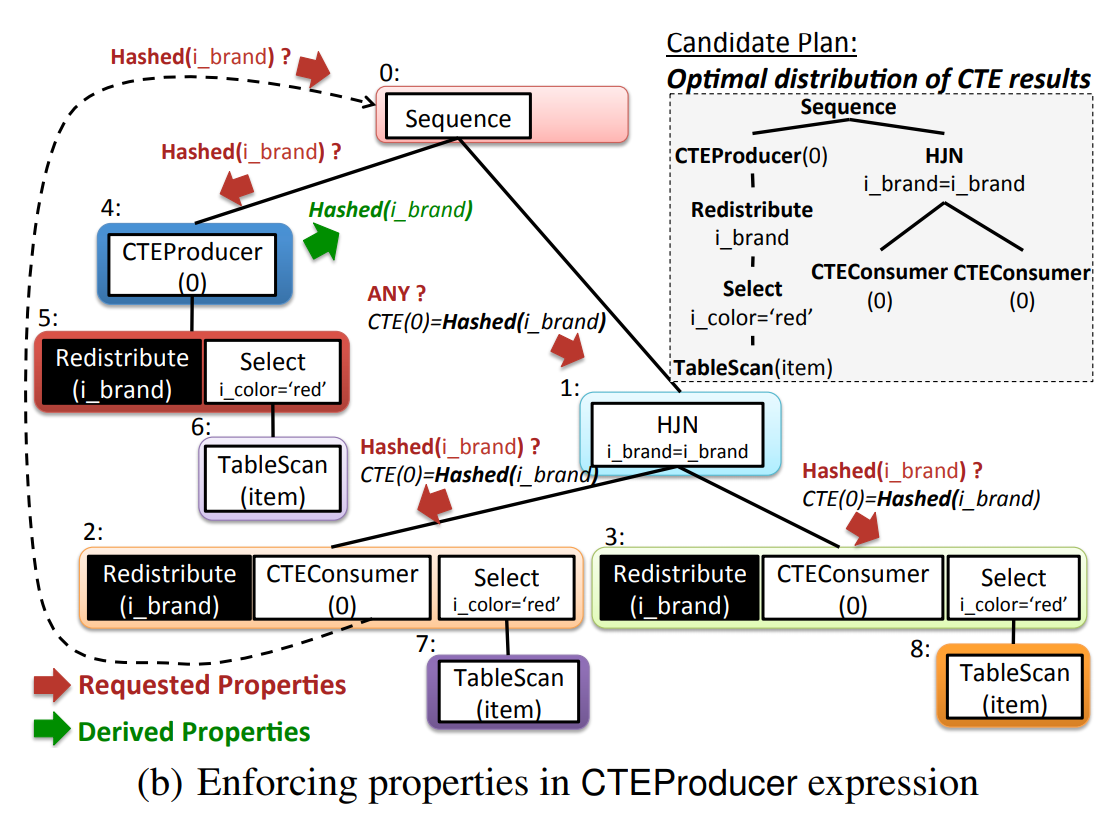
与 (a) 相比,(b) 中可以一开始就要求 CTE 按 i_brand 哈希分布,CTEProducer 会发现数据分布不满足要求,然后就可以在 group 5 中添加 Redistribute 的算子,CTEProducer 返回 Hashed(i_brand),这样 CTEConsumer 就不需要加上 Redistribute 的算子,最终得到一个最优的计划(CTEProducer 只需要计算一遍并保存数据,两个 CTEConsumer 意味着需要读取两遍数据)。
Cost Estimation
CTEProducer 和 CTEConsumer 的 cost 分开计算:
- CTEProducer 的 cost 是 CTE 自身的 cost,加上物化写磁盘的 cost
- CTEConsumer 的 cost 是读取物化结果的 cost,类似 scan 算子
参考
- El-Helw A, Raghavan V, Soliman M A, et al. Optimization of common table expressions in mpp database systems[J]. Proceedings of the VLDB Endowment, 2015, 8(12): 1704-1715.
- 《Optimization of Common Table Expressions in MPP Database Systems》论文导读