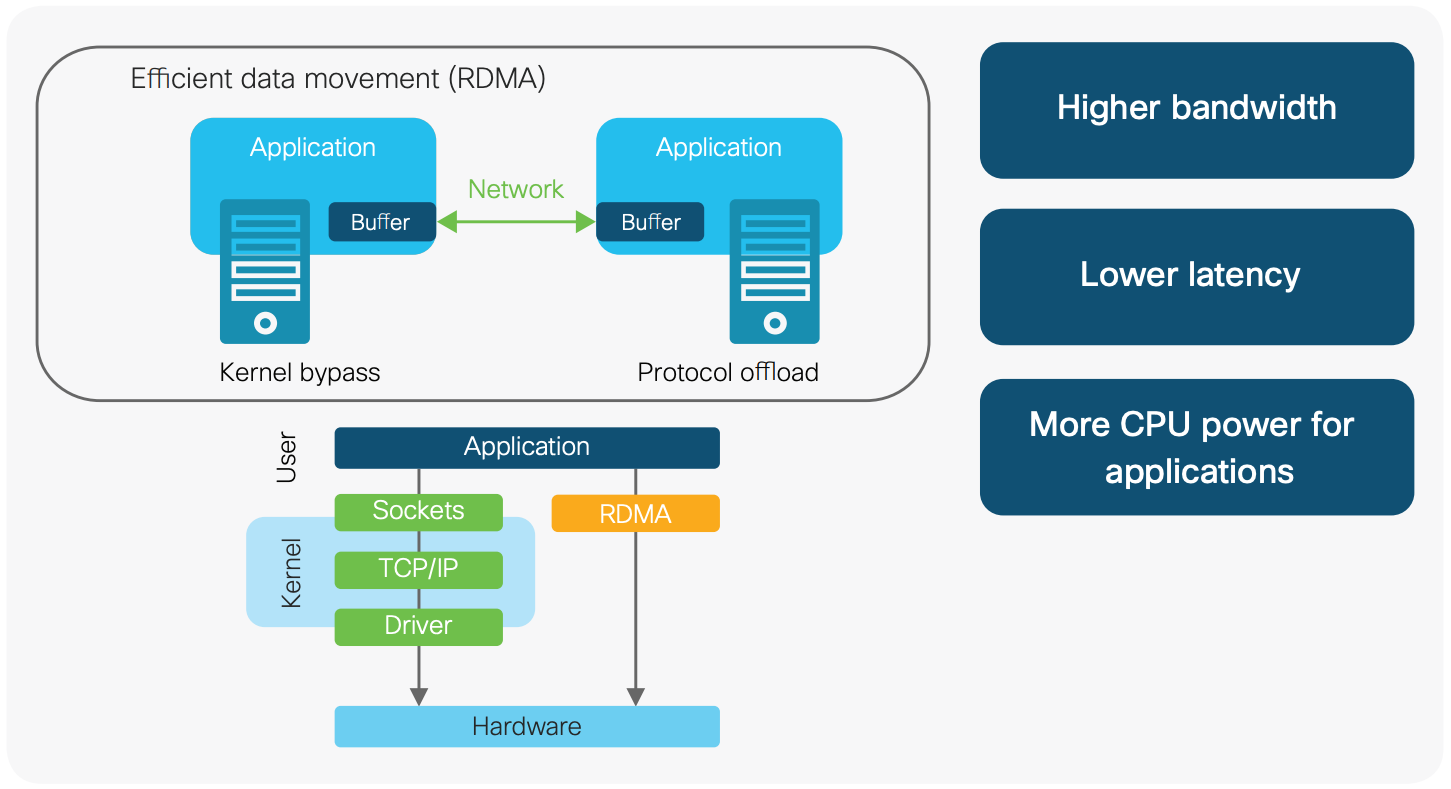
RDMA (Remote Direct Memory Access) refers to remote direct memory access, which is a method of transferring data in a buffer between two applications over a network.
- Remote: Data is transferred over a network with remote machines.
- Direct: Without the participation of the kernel, all information related to sending transmissions is offloaded to the network card.
- Memory: Data is transferred directly between user space virtual memory and the network card without involving the system kernel, with no additional data movement or copying.
- Access: Operations such as send, receive, read, write, atomic, etc.
RDMA is different from traditional network interfaces because it bypasses the operating system kernel. This gives programs that have implemented RDMA the following characteristics:
- Absolute minimum latency
- Highest throughput
- Smallest CPU footprint (that is, areas where CPU involvement is minimized)
RDMA Working Principles
During the RDMA communication process, for both sending and receiving, and read/write operations, the network card directly transfers data with the memory region that has already been registered for data transfer. This process is fast, does not require CPU participation, and the RDMA network card takes over the work of the CPU, saving resources for other calculations and services.
The working process of RDMA is as follows:
- When an application performs an RDMA read or write request, it doesn’t perform any data copying. Under the condition that no kernel memory is required, the RDMA request is sent from the application running in user space to the local network card.
- The network card reads the content of the buffer and transmits it to the remote network card over the network.
- The RDMA information transmitted over the network includes the virtual memory address of the target machine and the data itself. The completion of the request can be completely handled in user space (by polling the RDMA completion queue in user space). RDMA operations enable applications to read data from or write data to the memory of a remote application.
Therefore, RDMA can be simply understood as the use of relevant hardware and network technology, allowing the network card to directly read and write the memory of a remote server, ultimately achieving high bandwidth, low latency, and low resource utilization effects. The application does not need to participate in the data transmission process, it only needs to specify the memory read/write address, start the transmission, and wait for the transmission to complete.
RDMA Data Transmission
RDMA Send/Recv
This is similar to TCP/IP’s send/recv, but different in that RDMA is based on a message data transfer protocol (not a byte stream transfer protocol), and all packet assemblies are done on RDMA hardware. This means that the bottom 4 layers of the OSI model (Transport Layer, Network Layer, Data Link Layer, Physical Layer) are all completed on RDMA hardware.
RDMA Read
The essence of RDMA read operation is a Pull operation, pulling data from remote system memory back to local system memory.
RDMA Write
The essence of RDMA write operation is a Push operation, pushing data from local system memory to remote system memory.
RDMA Write with Immediate Data (RDMA write operation supporting immediate data)
RDMA write operation supporting immediate data essentially pushes out-of-band data to the remote system, which is similar to out-of-band data in TCP. Optionally, an Immediate 4-byte value can be sent along with the data buffer. This value is presented as part of the receipt notice to the receiver and is not included in the data buffer.
RDMA Programming Basics
To use RDMA, we need a network card that supports RDMA communication (i.e., implements the RDMA engine). We call this card an HCA (Host Channel Adapter). Through the PCIe (peripheral component interconnect express) bus, the adapter creates a channel from the RDMA engine to the application’s memory. A good HCA will implement all the logic needed for the executed RDMA protocol on hardware. This includes packetization, reassembly as well as traffic control and reliability assurance. Therefore, from the perspective of the application, it only needs to handle all the buffers.
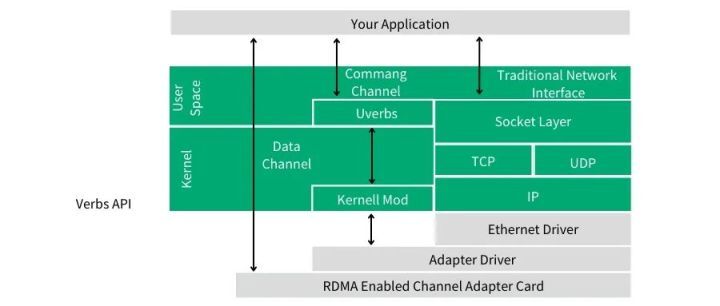
As shown in the above figure, in RDMA programming, we use the command channel to call the kernel mode driver to establish the data channel, which allows us to completely bypass the kernel when moving data. Once this data channel is established, we can directly read and write the data buffer. The API to establish a data channel is an API called verbs. The verbs API is maintained by a Linux open-source project called the Open Fabrics Enterprise Distribution (OFED).
Key Concepts
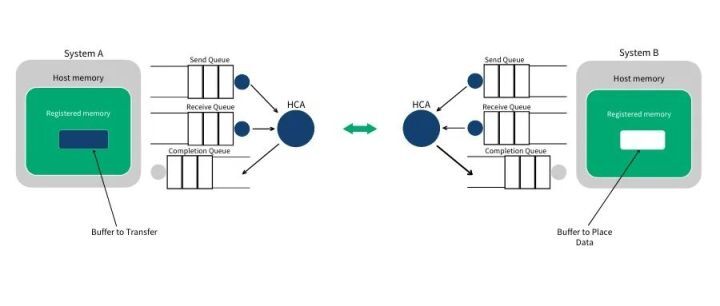
RDMA operation starts with memory operation. When you operate on memory, you are telling the kernel that this segment of memory is occupied by your application. So, you tell the HCA to address on this segment of memory and prepare to open a channel from the HCA card to this memory. We call this action registering a memory region MR (Memory Region). When registering, you can set the read and write permissions of the memory region (including local write, remote read, remote write, atomic, and bind). The Verbs API ibv_reg_mr can be used to register MR, which returns the remote and local keys of MR. The local key is used for the local HCA to access local memory. The remote key is provided to the remote HCA to access local memory. Once the MR is registered, we can use this memory for any RDMA operation. In the figure below, we can see the registered memory region (MR) and the buffer located within the memory region used by the communication queue.
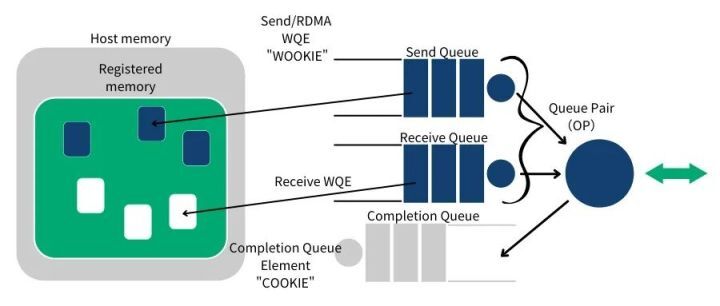
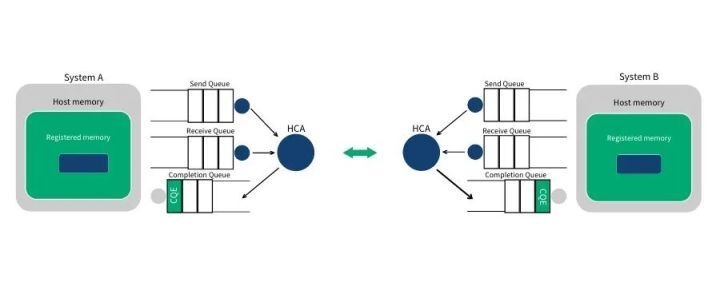
RDMA communication is based on a collection of three queues SQ (Send Queue), RQ (Receive Queue), and CQ (Completion Queue). The Send Queue (SQ) and Receive Queue (RQ) are responsible for scheduling work, they are always created in pairs, called Queue Pair (QP). The Completion Queue (CQ) is used to send notifications when instructions placed on the work queue are completed.
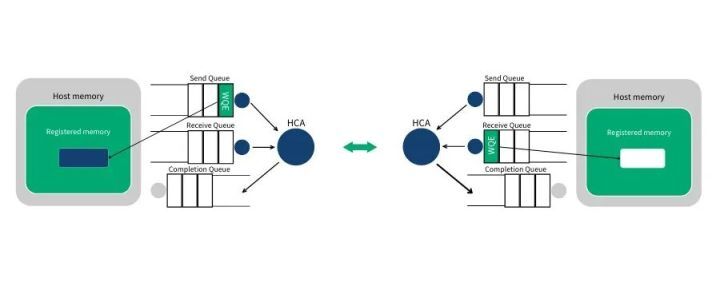
When a user places instructions on the work queue, it means telling the HCA which buffers need to be sent or used to receive data. These instructions are small structures, called Work Requests (WR) or Work Queue Elements (WQE). A WQE mainly contains a pointer to a buffer. A WQE placed in the Send Queue (SQ) contains a pointer to a message to be sent; a pointer in a WQE placed in the Receive Queue points to a buffer, which is used to store the message to be received.
RDMA is an asynchronous transmission mechanism. Therefore, we can place multiple send or receive WQEs in the work queue at once. The HCA will process these WQEs as quickly as possible in order. When a WQE is processed, the data is moved. Once the transmission is completed, the HCA creates a Completion Queue Element (CQE) with a successful status and places it in the Completion Queue (CQ). If the transmission fails for some reason, the HCA also creates a CQE with a failed status and places it in the CQ.
Example (Send/Recv)
Step 1: Both system A and B create their own QPs and CQs, and register the corresponding memory regions (MR) for the upcoming RDMA transfer. System A identifies a buffer, the data of which will be moved to system B. System B allocates an empty buffer to store data sent from system A.
Step 2: System B creates a WQE and places it in its Receive Queue (RQ). This WQE contains a pointer, which points to a memory buffer to store received data. System A also creates a WQE and places it in its Send Queue (SQ), the pointer in the WQE points to a memory buffer, the data of which will be transmitted.
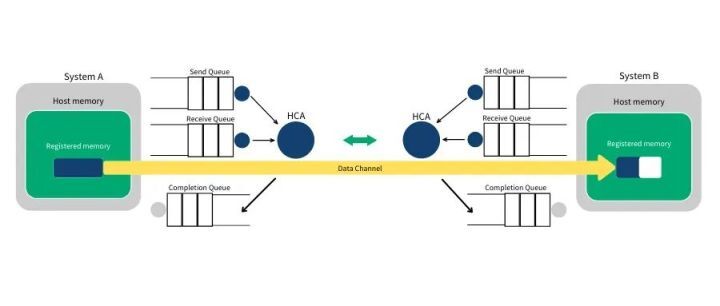
Step 3: The HCA on system A always works on hardware, checking if there are any WQEs in the send queue. The HCA will consume the WQE from system A and send the data in the memory region to system B as a data stream. When the data stream starts to arrive at system B, the HCA on system B consumes the WQE from system B and puts the data into the designated buffer. The data stream transmitted on the high-speed channel completely bypasses the operating system kernel.
Note: The arrows on the WQE represent pointers (addresses) to user space memory. In receive/send mode, both parties need to prepare their own WQEs (WorkQueue) in advance, and the HCA will write (CQ) after completion.
Step 4: When the data movement is completed, the HCA creates a CQE. This CQE is placed in the Completion Queue (CQ), indicating that data transmission has been completed. The HCA creates a CQE for each consumed WQE. Therefore, placing a CQE in the completion queue of system A means that the send operation of the corresponding WQE has been completed. Similarly, a CQE will also be placed in the completion queue of system B, indicating that the receive operation of the corresponding WQE has been completed. If an error occurs, the HCA will still create a CQE. The CQE contains a field to record the transmission status.
In IB or RoCE, the total time to transmit data in a small buffer is about 1.3µs. By simultaneously creating a lot of WQEs, data stored in millions of buffers can be transmitted in one second.
RDMA Operation Details
In RDMA transfer, Send/Recv is a bilateral operation, i.e., it requires the participation of both communicating parties, and Recv must be executed before Send so that the other party can send data. Of course, if the other party does not need to send data, the Recv operation can be omitted. Therefore, this process is similar to traditional communication. The difference lies in RDMA’s zero-copy network technology and kernel bypass, which results in low latency and is often used for transmitting short control messages.
Write/Read is a unilateral operation, as the name suggests, read/write operations are executed by one party. In actual communication, Write/Read operations are executed by the client, and the server does not need to perform any operations. In RDMA Write operation, the client pushes data directly from the local buffer into the continuous memory block in the remote QP’s virtual space (physical memory may not be continuous). Therefore, it needs to know the destination address (remote addr) and access rights (remote key). In RDMA Read operation, the client directly fetches data from the continuous memory block in the remote QP’s virtual space and pulls it into the local destination buffer. Therefore, it needs the memory address and access rights of the remote QP. Unilateral operations are often used for bulk data transfer.
It can be seen that in the unilateral operation process, the client needs to know the remote addr and remote key of the remote QP. These two pieces of information can be exchanged through Send/Recv operations.
RDMA Unilateral Operation (READ/WRITE)
READ and WRITE are unilateral operations, where only the source and destination addresses of the information need to be clearly known at the local end. The remote application does not need to be aware of this communication, and the reading or writing of data is completed through RDMA between the network card and the application Buffer, and then returned to the local end by the remote network card as encapsulated messages.
For unilateral operations, take storage in the context of a storage network as an example, the READ process is as follows:
- First, A and B establish a connection, and the QP has been created and initialized.
- The data is archived at B’s buffer address VB. Note that VB should be pre-registered with B’s network card (and it is a memory region) and get the returned remote key, which is equivalent to the permission to operate this buffer with RDMA.
- B encapsulates the data address VB and key into a dedicated message and sends it to A, which is equivalent to B handing over the operation right of the data buffer to A. At the same time, B registers a WR in its WQ to receive the status returned by A for data transmission.
- After A receives the data VB and remote key sent by B, the network card will package them together with its own storage address VA into an RDMA READ request and send this message request to B. In this process, both A and B can store B’s data to A’s VA virtual address without any software participation.
- After A completes the storage, it will return the status information of the entire data transfer to B.
The WRITE process is similar to READ. The unilateral operation transmission method is the biggest difference between RDMA and traditional network transmission. It only needs to provide direct access to the remote virtual address, and does not require remote applications to participate, which is suitable for bulk data transmission.
RDMA Bilateral Operation (SEND/RECEIVE)
SEND/RECEIVE in RDMA is a bilateral operation, that is, the remote application must be aware of and participate in the completion of the transmission and reception. In practice, SEND/RECEIVE is often used for connection control messages, while data messages are mostly completed through READ/WRITE.
Taking the bilateral operation as an example, the process of host A sending data to host B (hereinafter referred to as A and B) is as follows:
- First of all, A and B must create and initialize their own QP and CQ.
- A and B register WQE in their own WQ. For A, WQ = SQ, WQE describes a data that is about to be sent; for B, WQ = RQ, WQE describes a Buffer for storing data.
- A’s network card asynchronously schedules to A’s WQE, parses that this is a SEND message, and sends data directly to B from the buffer. When the data stream arrives at B’s network card, B’s WQE is consumed, and the data is directly stored in the storage location pointed to by the WQE.
- After A and B communication is completed, a completion message CQE will be generated in A’s CQ indicating that the sending is completed. At the same time, a completion message will be generated in B’s CQ indicating that the reception is completed. The processing of each WQE in WQ will generate a CQE.
Bilateral operation is similar to the underlying Buffer Pool of traditional networks, and there is no difference in the participation process of the sender and receiver. The difference lies in zero-copy and kernel bypass. In fact, for RDMA, this is a complex message transmission mode, often used for transmitting short control messages.
References
- https://xie.infoq.cn/article/49103d9cf895fa40a5cd397f8
- https://zhuanlan.zhihu.com/p/55142557
- https://zhuanlan.zhihu.com/p/55142547