Octopus: an RDMA-enabled Distributed Persistent Memory File System
概述
Octopus 通过 NVM + RDMA 实现了分布式文件系统,主要贡献总结如下:
- 提出了基于 RDMA 的新型 I/O 流,它直接访问持久化共享内存池,而无需经过文件系统层层调用,并在客户端主动获取或发送数据以重新平衡服务器和网络负载。
- 利用 RDMA 原语重新设计元数据机制,包括自标识元数据 RPC 来用于低延迟通知,以及收集-调度分布式事务实现低一致性开销。
- 有效地利用了硬件性能,显著优于现有 RDMA 优化的分布式文件系统。
挑战
- 之前由于存储介质较慢,访问持久化存储介质的开销几乎占据了文件系统操作的全部,软件栈的优化对整体性能的影响微乎其微,所以之前的存储层与网络层往往采用松耦合的设计模式来使得系统更容易理解与实现。而对于 NVM 上的文件系统来说,由于 NVM 的访问时延接近内存,使得软件栈的开销几乎占据了文件系统操作的全部,现在优化软件栈开销成为优化系统最重要的手段。
- 现有的文件系统利用新硬件高带宽的效率低下。这主要有四个原因:(1)数据在应用缓冲区、文件系统页缓存、网卡缓冲等区域之间来回拷贝,增加了软件开销;(2)服务器每秒需要处理的大量请求,server 端 CPU 成为瓶颈;(3)基于事件驱动模型的传统 RPC 具有相对较高的延迟;(4)分布式文件系统中使用到的分布式事务等需要多次的网络来回,处理逻辑较为复杂,使得分布式文件系统用在一致性上的开销较大。
设计
总体架构
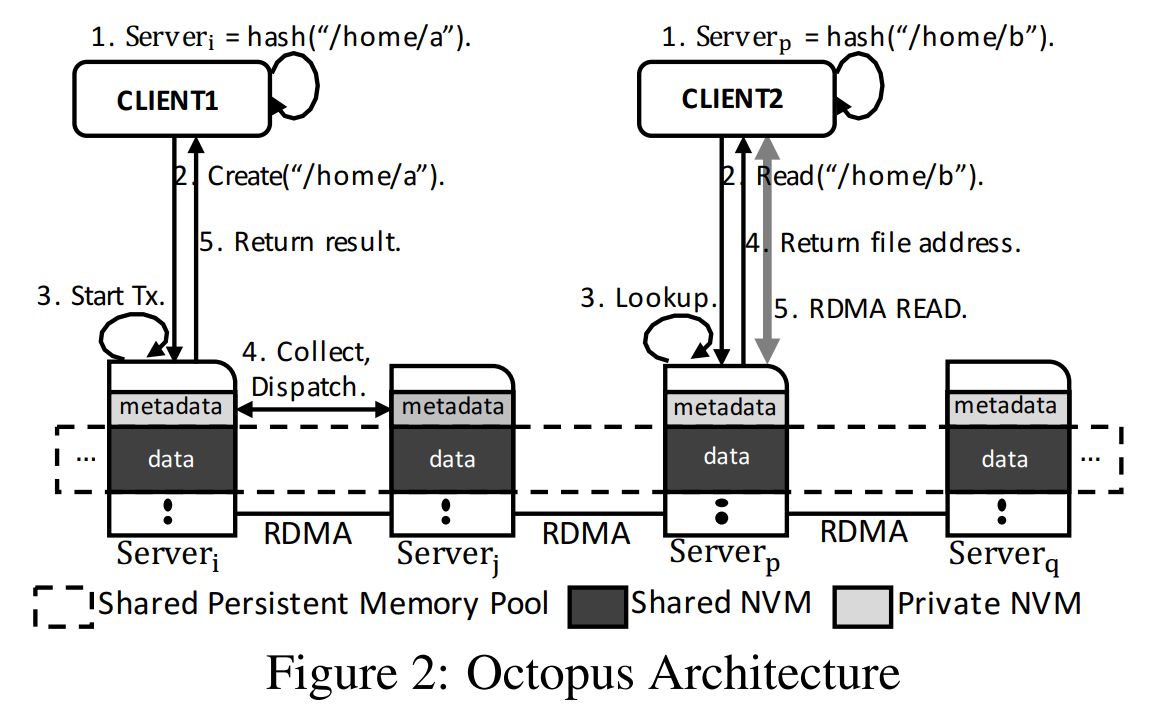
Octopus 文件系统数据分散在集群节点中,一个文件根据路径名使用一致性哈希保存在一个节点中,文件没有做冗余,RDMA 与存储层紧耦合设计。
每个节点的 NVM 分为私有部分和共享部分。私有部分保存该节点文件的元数据,只允许本节点内访问,客户端通过 RPC 访问;共享部分保存该节点中文件的数据,客户端可以通过 RDMA 单边原语直接读写。Octopus 使用 RDMA write-with-imm 进行 RPC。
数据布局
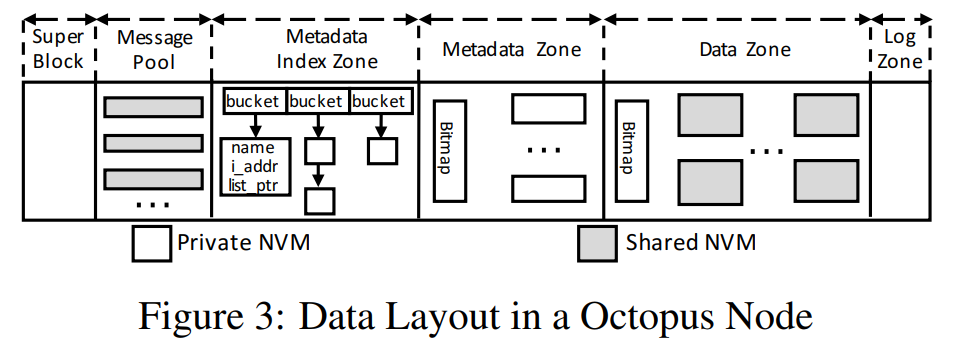
Octopus 每个节点的 NVM 划分为 6 个区域,每个区域是共享的或私有的。这六个区域的内容为:
- Super Block:用于存储文件系统的超级块
- Message Pool:元数据 RPC 的通信缓冲区
- Metadata Index Zone:使用哈希表保存文件索引
- Metadata Zone:具体的文件元数据保存区域
- Data Zone:文件数据的保存区域
- Log Zone:事务日志区域
High-Throughput Data I/O
Octopus 引入了共享持久化内存池来减少数据拷贝以获得更高的带宽,并且在客户端主动执行 I/O 来重新平衡服务器和网络开销以获得更高的吞吐量。
Shared Persistent Memory Pool
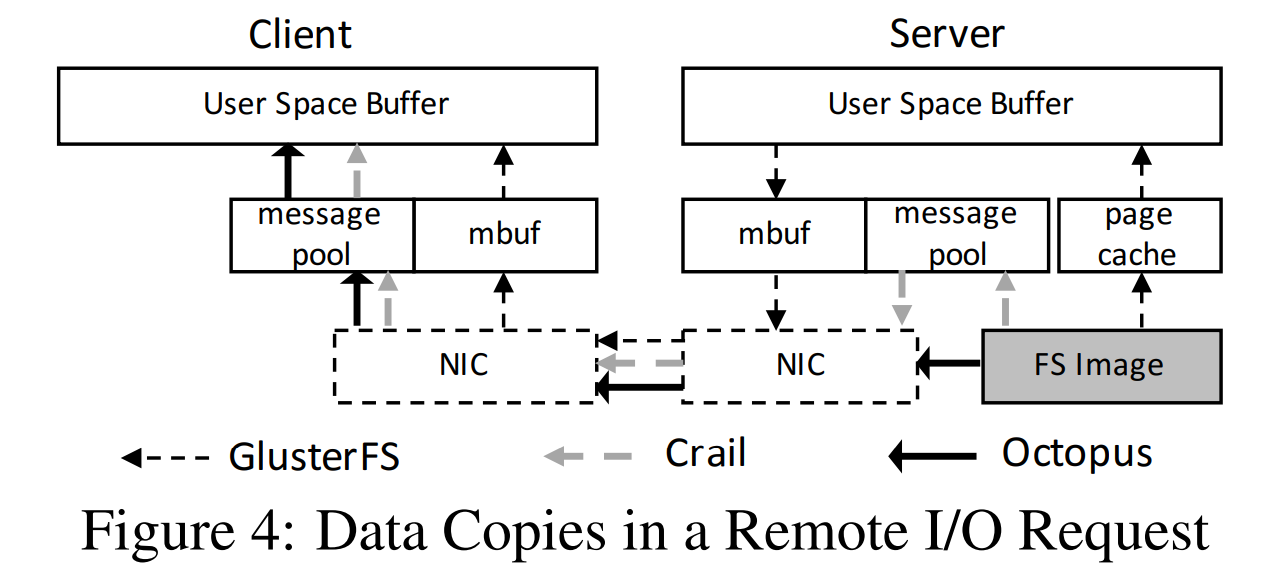
如图所示,GlusterFS 里同一个数据在传输过程中拷贝了 7 次,Octopus 利用共享持久化内存池取消层次抽象,以及通过 RDMA 取消缓存,将数据拷贝降低到了 4 次。
Client-Active Data I/O
Octopus 提出了 Client-Active Data I/O 数据访问模式,充分发挥了 RDMA 的优势,降低了服务端 CPU 的负载。
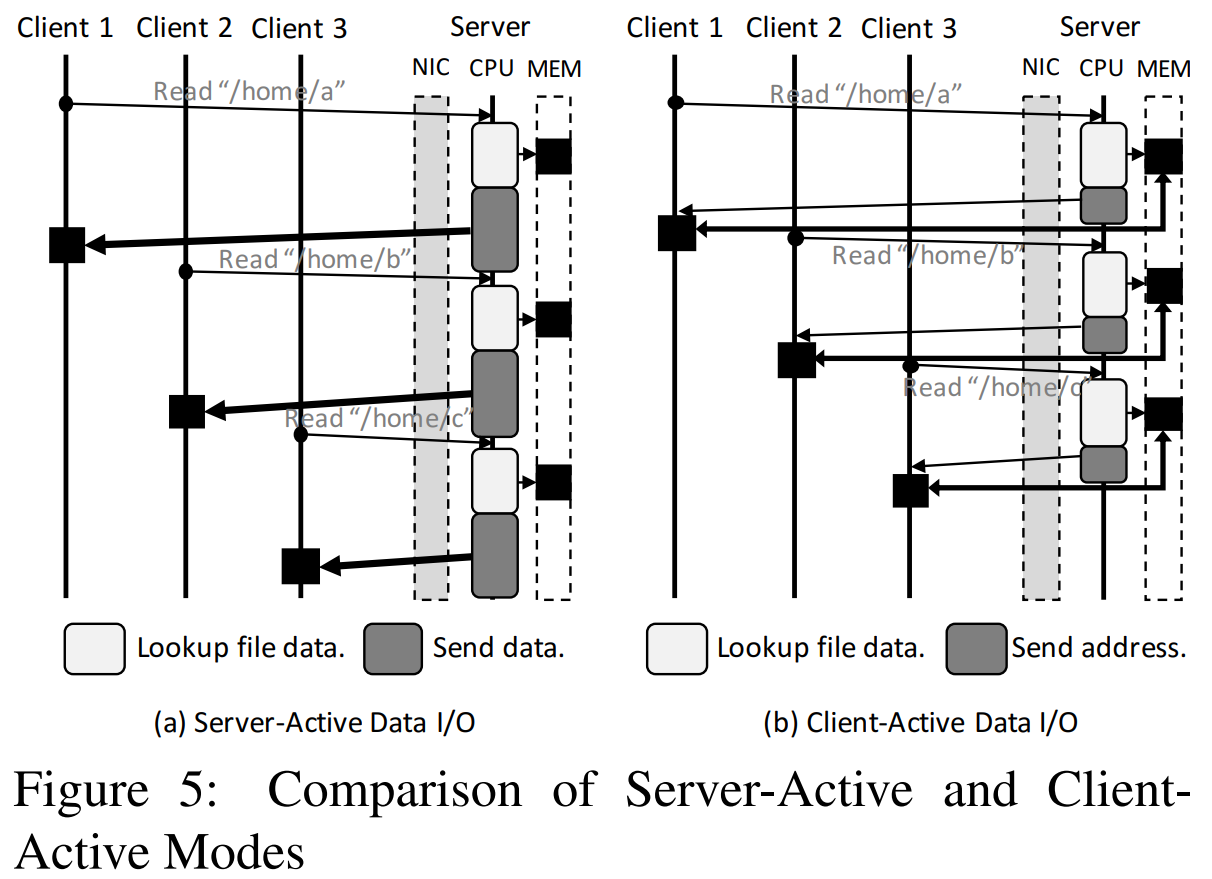
传统的数据交互为 Server-Active Data I/O 方式,如图中的(a)所示,客户端给服务端发送数据访问请求,服务端查找到数据的位置后读取对应的数据,并把最终的数据返回给客户端。而 Client-Active Data I/O 方式则与此不同,如图中的(b)所示,客户端使用自标识元数据 RPC 发送读写请求和访问元数据,然后根据元数据信息使用 RDMA Read/Write 直接读写文件数据。
Client-Active 与 Server-Active 相比,服务端 CPU 执行一个请求的操作较少,将读数据操作转移给了客户端进行,从而降低了服务端 CPU 的负载。
Low-Latency Metadata Access
RDMA 为远程数据访问提供微秒级访问延迟。为了在文件系统发挥这一优势,Octopus 通过合并 RDMA 写入和原子原语重构了元数据 RPC 和分布式事务。
Self-identified metadata RPC
RDMA 具有低延迟高带宽的优势,在 RPC 中使用 RDMA 能够提高吞吐量。以往的 RDMA RPC 大多使用双边 RDMA 原语,而双边 RDMA 具有相对较高的延迟和较低的吞吐量,减小了 RDMA 的优势。而单边 RDMA 原语不会在完成时通知 CPU,若使用单边 RDMA 进行 RPC,服务器需要有单独的线程轮询消息缓冲区,使 CPU 的负载进一步增大。
为了保持 RDMA 低延迟的优势并减少 CPU 的负载,Octopus 提出了 Self-identified metadata RPC(自标识元数据 RPC)。自标识元数据 RPC 使用 RDMA write_with_imm 命令将发送者的标识信息附加到 RDMA 请求中。write_with_imm 与传统的 RDMA Write 相比有以下两点不同:(1) 它能够在消息中携带一个立即数;(2)它能够在服务器网卡接收到该请求后立即通知服务器 CPU,这会消耗服务器的 QP 中的一个 Recv WR。因此,使用 write_with_imm 能够让服务器及时收到 RPC 请求,且无需 CPU 进行轮询。立即数字段中附加有客户端标识符 node_id 和客户端接收缓冲区的 offset。node_id 可帮助服务器定位对应消息而无需扫描整个缓冲区。请求处理完成之后,服务器使用 RDMA Write 原语将数据返回到标识符为 node_id 的客户端中偏移量地址 offset 处。
Collect-Dispatch Transaction
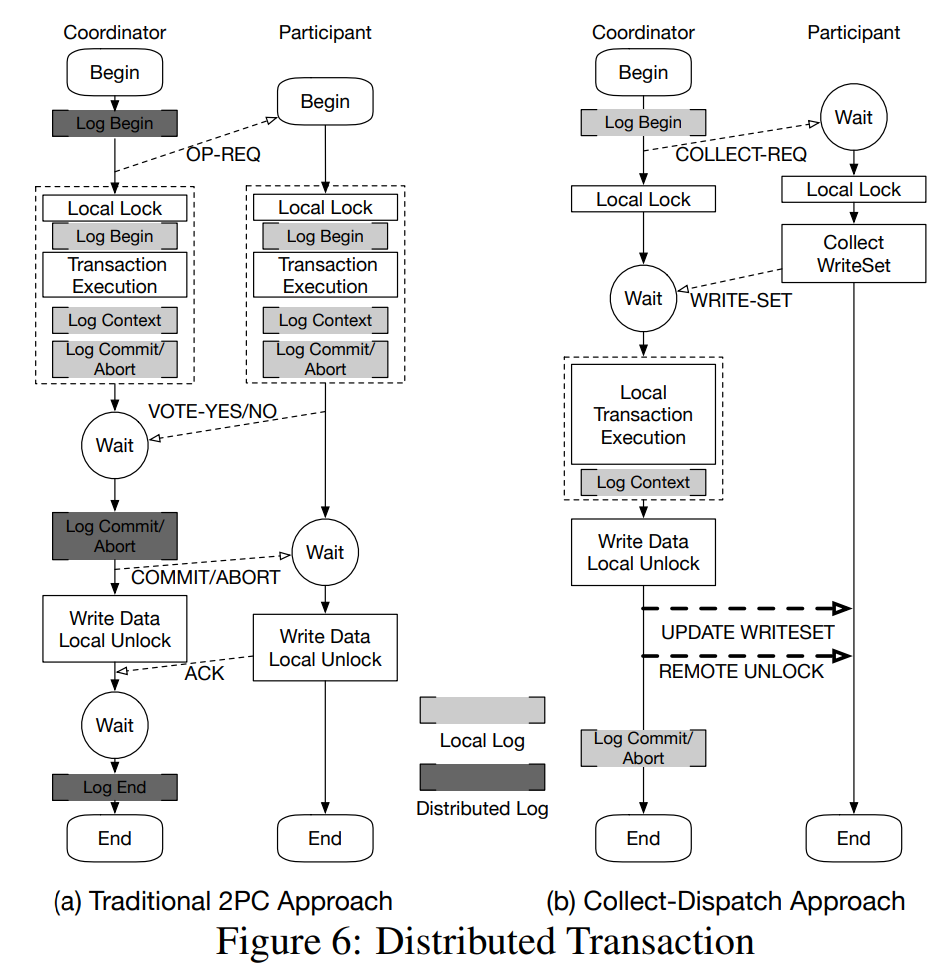
在文件系统中,某些操作可能会使用分布式事务进行,如 mkdir,mknod,rmnod 和 rmdir 等等。这些操作需要在多个服务器之间原子性地更新元数据。在之前的分布式文件系统中,往往使用两阶段提交(2PC)完成事务操作。然而两阶段提交由于其分布式的日志以及对锁和日志的协调而导致高昂的开销。
Octopus 设计了一个新的分布式事务协议:Collect-Dispatch Transaction,该协议分为收集阶段(Collect Phase)和分发阶段(Dispatch Phase)。该事务协议利用了 RDMA 原语进行服务器间的交互,关键思想在于两个方面,分别是崩溃一致性和并发控制:
- 带有远程更新的本地日志来实现崩溃一致性。在收集阶段,Octopus 从参与者收集读写集合,并在协调者中执行本地事务,记录日志。由于参与者不需要保留日志记录,因此无需为协调者和参与者之间的持久化日志进行复杂的协商,从而减少了协议的开销。在分发阶段,协调者使用 RDMA write 将更新的写集合分发给参与者,并使用 RDMA atomic 原语释放相应的锁,而不涉及到参与者 CPU。
- 混合使用 GCC 和 RDMA 锁来实现并发控制。在 Collect-Dispatch 事务中,协调者和参与者使用 GCC 的 Compare-and-Swap 命令在本地添加锁。解锁时,协调者使用 GCC 的 Compare-and-Swap 命令释放本地锁,并使用 RDMA 的 Compare-and-Swap 命令释放远端每个参与者的锁,解锁操作不涉及到参与者的 CPU,因此优化了解锁阶段。
总的来说,Collect-Dispatch Transaction 需要一次 RPC(COLLECT-REQ 和 WRITE-SET)、一次 RDMA Write(UPDATE WRITESET)和一次 RDMA Atomic(REMOTE UNLOCK),而两阶段提交需要两次 RPC。Collect-Dispatch Transaction 与 2PC 相比具有较低的开销,这是因为:(1) 一次 RPC 比一次 RDMA Write/Atomic 原语具有更高的延迟;(2) RDMA Write/Atomic 原语不需要服务端 CPU 的介入。
总结
Octopus 其核心思想是 RDMA 与 NVM 紧耦合设计,设计了一系列机制来实现高吞吐量的数据 I/O 以及低延迟的元数据访问。但在分布式方面该文件系统没有做冗余,也没有考虑负载均衡等内容,只是通过一致性哈希将数据分散到不同节点上。
参考
- Lu, Youyou, et al. “Octopus: An RDMA-Enabled Distributed Persistent Memory File System.” USENIX ATC ’17 Proceedings of the 2017 USENIX Conference on Usenix Annual Technical Conference, 2017, pp. 773–785.