From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees
背景
Bourbon 基于 WiscKey(比 LevelDB 和 RocksDB 更快的 LSM-Tree 存储系统)实现。本文通过对 WiscKey 的实验分析,总结了五条指南。Bourbon 应用了这些指南,将 WiscKey 与学习索引相结合,利用学习索引实现快速查找。
设计与实现
Five learning guidelines
- Favor learning files at lower levels (生命周期更长)
- Wait before learning a file (连续的 compaction 会在每一层生成生命周期非常短的新文件)
- Do not neglect files at higher levels (可以提供多种内部查询方式)
- Be workload- and data-aware (在不同的场景中查找会有很大差异)
- Do not learn levels for write-heavy workloads (变化很快)
Beneficial regimes
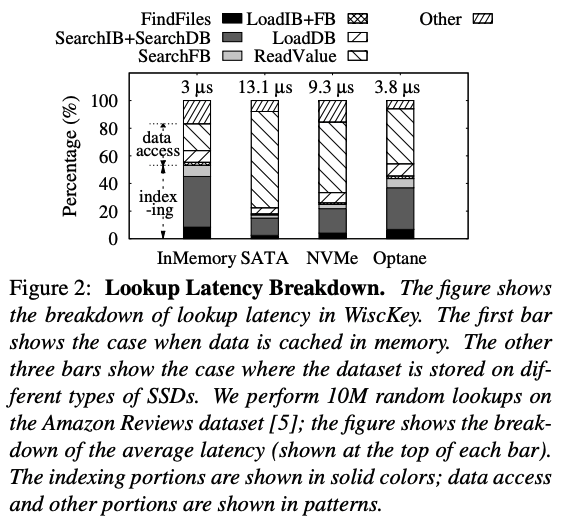
学习索引只能缩短检索时间。
Bourbon Learning
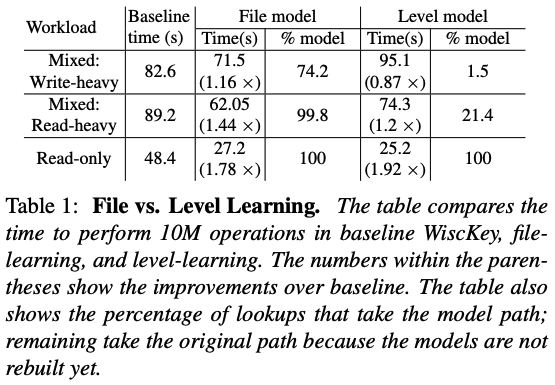
Bourbon 使用分段线性回归(PLR)对数据进行建模,PLR 在学习和查找过程中开销较低,而且空间开销也很小。Bourbon 可以学习单个 SSTables文件(File Learning)或整个层级(Level Learning)。层级学习对于只读工作负载收益更高,而对于混合工作负载,层级学习的性能不如文件学习。
为了训练 PLR 模型,Bourbon 使用了 Greedy-PLR 算法,一次处理一个数据点,如果数据点不能在不超出定义的误差限制的情况下被添加到当前的线段中,那么将创建一个新的线段,并将数据点添加到其中,最终 Greedy-PLR 生成了一组代表数据的线段。Greedy-PLR 的运行时间与数据点的数量呈线性关系。
Cost-benefit analyzer (CBA)
成本效益分析(Cost-Benefit Analyzer, CBA)的目的是过滤掉不值得学习的生命周期较短的文件。CBA 在同一层级使用之前文件的统计信息。
为了过滤短生命周期文件,Bourbon 在学习文件之前会等待一个时间阈值 $T_{wait}$。对一个文件进行学习的最大耗时约为 40 毫秒,因此 Bourbon 将 $T_{wait}$ 设置为 50 毫秒。但是,学习一个长期存在的文件也可能没有好处。作者实验发现更低层级的文件通常寿命更长,对于有的工作负载和数据集,他们服务的查询操作比更高层级的文件要少得多。因此,除了考虑模型对应的开销以外,还需要考虑模型可能带来的收益。如果一个模型的收益($B_{model}$)大于构建该模型的开销($C_{model}$),那么该模型就是有利的。
Estimating the cost ($C_{model}$)
如果假定学习过程发生在后台(有很多空闲的 core),那么 $C_{model}$ 开销就为 0。不过 Bourbon 采取了保守的做法,假设学习线程会对系统产生干扰,导致性能变慢。因此,论文将 $C_{model}$ 开销定义为与 $T_{build}$ 相等,即文件训练 PLR 模型的时间。由于 $T_{build}$ 与文件中数据点的数量成线性比例,我们将 $T_{build}$ 定义为文件中数据点的数量与训练一个数据点的平均时间的乘积。
Estimating the benefit ($B_{model}$)
Bourbon 定义模型带来的收益如下:
$$
B_{model} = (T_b - T_m) * N
$$
- $T_{b}$: 在基线中查找的平均时间
- $T_{m}$: 在模型路径中查找的平均时间
- $N$: 文件在其生命周期内的查找次数
然后又将查询操作又划分成了 negative 和 positive,因为大多数 negative 的查询操作在 filter 处就终止了,所以最终的收益模型为:
$$
B_{model} = ((T_{n.b} - T_{n.m}) * N_n) + ((T_{p.b} - T_{p.m}) * N_p)
$$
- $N_{n}$ & $N_{p}$: negative 和 positive 的查询数量
- $T_{n.b}$ & $T_{p.b}$: 在基线中 negative 和 positive 查找的平均时间
- $T_{n.m}$ & $T_{p.m}$: 在模型路径中 negative 和 positive 查找的平均时间
为了估计查找次数($N_{n}$ & $N_{p}$)和查找所需时间($T_{n.b}$ & $T_{p.b}$),CBA 维护了这些文件在其生命周期内和在同一层级上的文件的统计信息(因为统计信息在不同层级之间存在显著差异)。
这些估算在 $T_{wait}$ 期间完成:
- $T_{n.b}$ & $T_{p.b}$: 在 $T_{wait}$ 期间,查询将通过基线路径,这些查询时间用于估计 $T_{n.b}$ 和 $T_{p.b}$
- $T_{n.m}$ & $T_{p.m}$: 通过同一层级所有其他文件的平均值进行估计
- $N_{n}$ & $N_{p}$: CBA 首先获取该层级中其他文件的平均 negative 查找和 positive 查找,然后,将其按 $f = s / s’$ 的倍数进行缩放,其中 $s$ 是文件的大小,$s’$ 是该层级的文件的平均大小
如果 $C_{model} < B_{model}$,文件将会开始训练。如果多个文件同时开始训练,则将它们放在一个最大优先级队列中,从而使收益最大的文件能够先被训练。
未来可能的改进方向包括:
- 对 $N_{n}$, $N_{p}$, $T_{n.m}$, $T_{p.m}$ 进行更精确的估计
- 改进计算 $C_{model}$ 开销的方法,使其不仅仅是 $T_{build}$
- 使用另外的函数对训练队列进行排序,而非 $B_{model} - C_{model}$
Bourbon: Putting it All Together
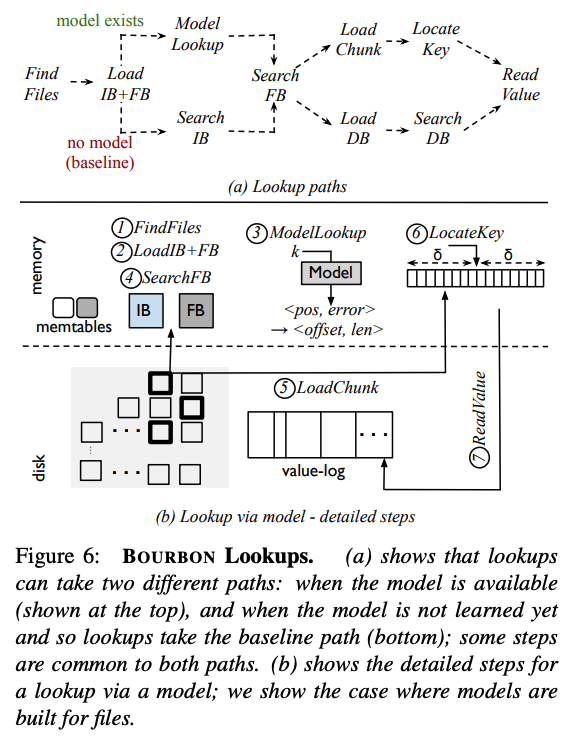
评估