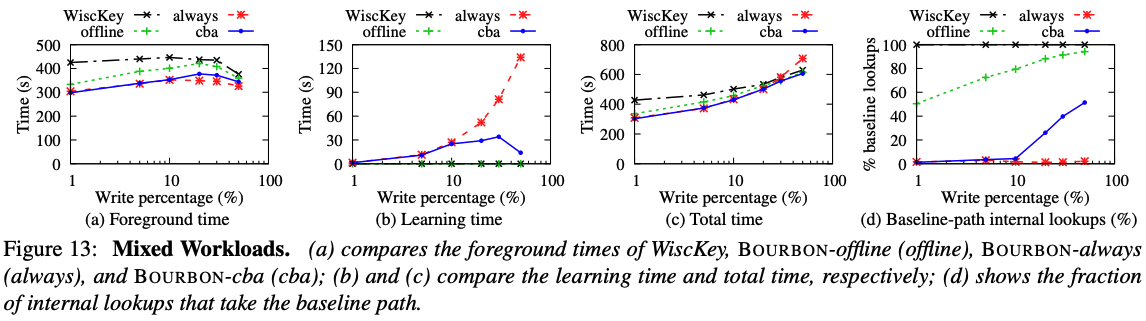
ALEX: An Updatable Adaptive Learned Index
概述
ALEX 是一个可更新的内存型学习索引。对比 B+Tree 和 Learned Index,ALEX 的目标是:(1)插入时间与 B+Tree 接近,(2)查找时间应该比 B+Tree 和 Learned Index 快,(3)索引存储空间应该比 B+Tree 和 Learned Index 小,(4)数据存储空间(叶子节点)应该与 B+Tree 相当。
ALEX 的设计如下:
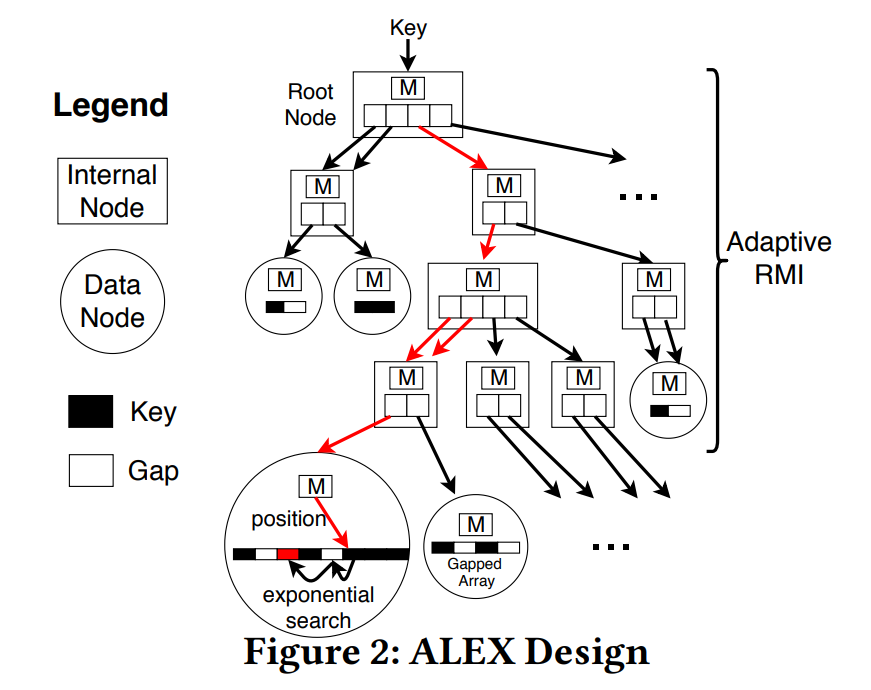
- ALEX 动态调整 RMI 的形状和高度,节点可以进行扩展和分割
- ALEX 使用 Exponential Search 来寻找叶子层的 key,以纠正 RMI 的错误预测,这比 Binary Search 效果更好
- ALEX 在数据节点上使用 Gapped Array(GA),将数据插入在自己预测的地方。这和 RMI 有很大的不同。RMI 是先排好序,让后训练模型去拟合数据。而 ALEX 是在模型拟合完数据后,将数据在按照模型的预测值插入到对应的地方,这大大降低了预测的错误率
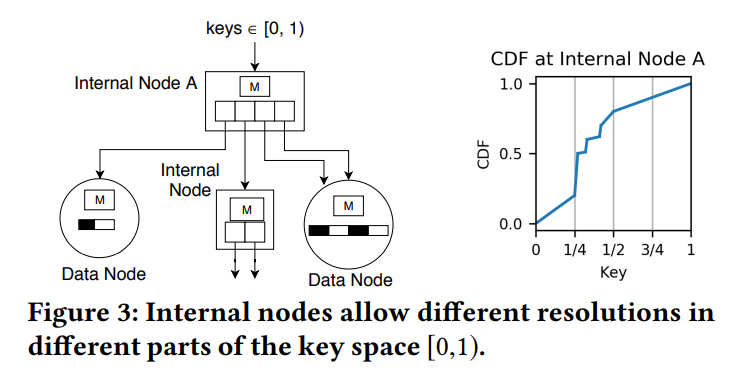
- ALEX 的 RMI 结构的目标不是产生同等大小的数据节点,而是产生 key 分布大致为线性的数据节点,以便线性模型能够准确地拟合。因此,ALEX 中的内部节点更加灵活。例如下图中节点 A 中 keys 的范围在 [0,1) 内,并有四个指针。ALEX 将 keys 范围 [0,1/4) 和 [1/2,1) 分配给数据节点(因为这些空间的 CDF 是线性的),并将 [1/4,1/2) 分配给另一个内部节点(因为CDF是非线性的,RMI需要对这个空间进行更多的划分)。另外,多个指针可以指向同一个子节点,便于插入;限制每个内部节点的指针数量总是 2 的幂,便于节点可以在不重新训练的情况下分裂
下面介绍 ALEX 的查询、插入、删除等步骤。
Lookups and Range Queries
查找时,从 RMI 的根节点开始,使用模型计算在哪一个位置,然后迭代地查询下一级的叶子节点,直到到达一个数据节点。在数据节点中使用模型来查询 key 在数组中的位置,如果预测失败,则进行 Exponential Search 以找到 key 的实际位置。如果找到了一个 key,读取对应值并返回记录,否则返回一个空记录。对于范围查询,首先找到第一个 key 的位置,该 key 不小于范围的起始值,然后扫描,直到到达范围的结束值,使用节点的 bitmap 跳过间隙,必要时跳到下一个数据节点。
Insert in non-full Data Node
插入逻辑与上述查找算法相同。在一个 non-full 的数据节点中,使用数据节点中的模型来预测插入位置。如果预测的位置不正确(不能保持有序),则做 Exponential Search 来找到正确的插入位置。如果插入位置为空,则直接插入,否则插入到最近的间隙中。Gapped Array实现了 O(logn) 插入时间。
Insert in full Data Node
Criteria for Node Fullness
ALEX 并不会让数据节点 100% 充满,因为在 Gapped Array 上的插入性能会随着间隙数量的减少而下降。需要在 Gapped Array 上引入了密度的下限和上限:dl, du ∈ (0, 1),约束dl < du。密度被定义为被元素填充的位置的百分比。如果下一次插入使得密度超过了 du,那么这个节点就是满的。默认情况下,我们设置 dl=0.6,du=0.8。相比之下,B+Tree 的节点通常有 dl=0.5 和 du=1。
Node Expansion Mechanism
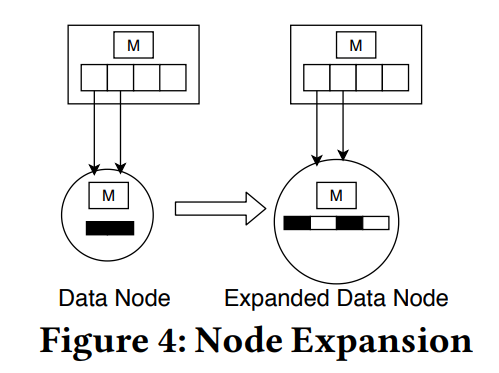
扩展一个包含 N 个 key 的数据节点,需要创建一个具有 N/dl 槽的新的较大的 Gapped Array。然后对线性回归模型进行缩放或重新训练,然后使用缩放或重新训练的模型对这个节点中的所有元素进行基于模型的插入。新的数据节点的密度处于下限 dl。下图为一个数据节点扩展的例子,数据节点内的 Gapped Array 从左边的两个槽扩展到右边的四个槽。
Node Split Mechanism
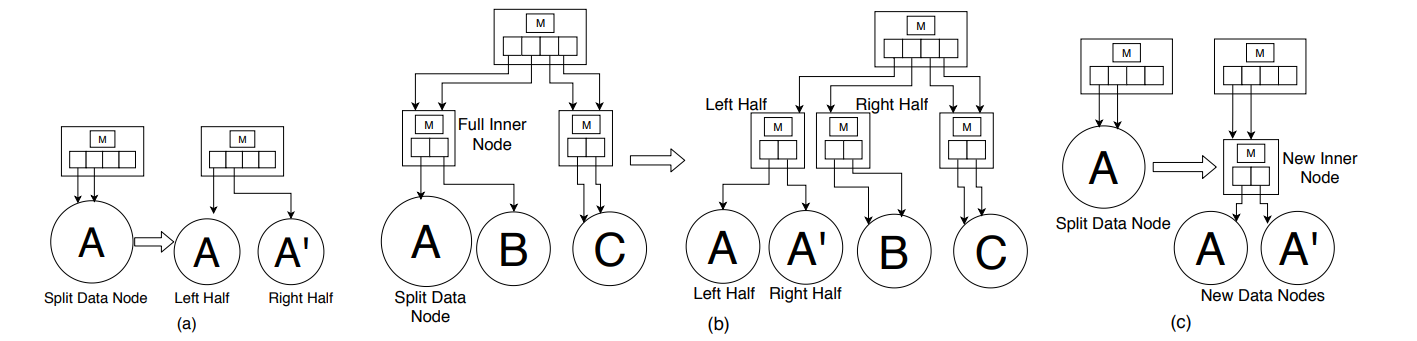
- 水平分裂。有两种情况:(1) 如果待分裂的数据节点的父内部节点还没有达到最大的节点大小,父内部节点的指针数组可能有多余的指向待分裂数据节点的指针。如果有,则各让一半的指针指向两个新数据节点。否则,将父节点的指针数组的大小增加一倍,并为每个指针制作一个冗余的副本,来创建第二个指向分裂数据节点的指针,然后再分裂。下图(a)展示了一个不需要扩展父内部节点的侧向分裂的例子。(2) 如果父内部节点已经达到最大节点大小,那么我们可以选择拆分父内部节点,如下图(b)中所示。因为内部节点的大小为2的幂,所以总是可以拆分一个数据节点,不需要对拆分后的任何模型进行重新训练。分裂可以一直传播到根节点,就像在 B+Tree 中一样。
- 向下分裂。如下图(c)所示,向下分裂将一个数据节点转换为具有两个子数据节点的内部节点。两个子数据节点中的模型是根据它们各自的 key 来训练的。
Delete and update
要删除一个 key,需要先找到该 key 的位置,然后删除它和它对应的值。删除不会移动任何现有的 key,所以删除是一个严格意义上的比插入更简单的操作,不会导致模型的准确性下降。如果一个数据节点由于删除而达到了密度下限 dl,那么就缩小数据节点(与扩大数据节点相反),以避免空间利用率过低。此外还可以使用节点内的成本模型来确定两个数据节点是否应该合并在一起,然而为了简单起见,ALEX 开源代码中并没有实现这些合并操作。
key 更新是通过结合插入和删除来实现的;值更新是通过查找 key 并将新值写入来实现的。